Compare commits
1 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
2778edbf4b |
@@ -21,23 +21,7 @@
|
||||
<!--If merged, your code will serve tens of thousands of users! Please double-check the following items before submitting.-->
|
||||
<!--如果分支被合并,您的代码将服务于数万名用户!在提交前,请核查一下几点内容。-->
|
||||
|
||||
- [ ] 😊 如果 PR 中有新加入的功能,已经通过 Issue / 邮件等方式和作者讨论过。
|
||||
/ If there are new features added in the PR, I have discussed it with the authors through issues/emails, etc.
|
||||
|
||||
- [ ] 👀 我的更改经过了良好的测试,**并已在上方提供了“验证步骤”和“运行截图”**。
|
||||
/ My changes have been well-tested, **and "Verification Steps" and "Screenshots" have been provided above**.
|
||||
|
||||
- [ ] 🤓 我确保没有引入新依赖库,或者引入了新依赖库的同时将其添加到 `requirements.txt` 和 `pyproject.toml` 文件相应位置。
|
||||
/ I have ensured that no new dependencies are introduced, OR if new dependencies are introduced, they have been added to the appropriate locations in `requirements.txt` and `pyproject.toml`.
|
||||
|
||||
- [ ] 😮 我的更改没有引入恶意代码。
|
||||
/ My changes do not introduce malicious code.
|
||||
|
||||
- [ ] ⚠️ 我已认真阅读并理解以上所有内容,确保本次提交符合规范。
|
||||
/ I have read and understood all the above and confirm this PR follows the rules.
|
||||
|
||||
- [ ] 🚀 我确保本次开发**基于 dev 分支**,并将代码合并至**开发分支**(除非极其紧急,才允许合并到主分支)。
|
||||
/ I confirm that this development is **based on the dev branch** and will be merged into the **development branch**, unless it is extremely urgent to merge into the main branch.
|
||||
|
||||
- [ ] ⚠️ 我**没有**认真阅读以上内容,直接提交。
|
||||
/ I **did not** read the above carefully before submitting.
|
||||
- [ ] 😊 如果 PR 中有新加入的功能,已经通过 Issue / 邮件等方式和作者讨论过。/ If there are new features added in the PR, I have discussed it with the authors through issues/emails, etc.
|
||||
- [ ] 👀 我的更改经过了良好的测试,**并已在上方提供了“验证步骤”和“运行截图”**。/ My changes have been well-tested, **and "Verification Steps" and "Screenshots" have been provided above**.
|
||||
- [ ] 🤓 我确保没有引入新依赖库,或者引入了新依赖库的同时将其添加到了 `requirements.txt` 和 `pyproject.toml` 文件相应位置。/ I have ensured that no new dependencies are introduced, OR if new dependencies are introduced, they have been added to the appropriate locations in `requirements.txt` and `pyproject.toml`.
|
||||
- [ ] 😮 我的更改没有引入恶意代码。/ My changes do not introduce malicious code.
|
||||
|
||||
@@ -1,45 +0,0 @@
|
||||
name: PR Checklist Check
|
||||
|
||||
on:
|
||||
pull_request_target:
|
||||
types: [opened, edited, reopened, synchronize]
|
||||
|
||||
jobs:
|
||||
check:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
permissions:
|
||||
pull-requests: write
|
||||
issues: write
|
||||
|
||||
steps:
|
||||
- name: Check checklist
|
||||
id: check
|
||||
uses: actions/github-script@v7
|
||||
with:
|
||||
script: |
|
||||
const body = context.payload.pull_request.body || "";
|
||||
const regex = /-\s*\[\s*x\s*\].*没有.*认真阅读/i;
|
||||
const bad = regex.test(body);
|
||||
core.setOutput("bad", bad);
|
||||
|
||||
- name: Close PR
|
||||
if: steps.check.outputs.bad == 'true'
|
||||
uses: actions/github-script@v7
|
||||
with:
|
||||
script: |
|
||||
const pr = context.payload.pull_request;
|
||||
|
||||
await github.rest.issues.createComment({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
issue_number: pr.number,
|
||||
body: `检测到你勾选了“我没有认真阅读”,PR 已关闭。`
|
||||
});
|
||||
|
||||
await github.rest.pulls.update({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
pull_number: pr.number,
|
||||
state: "closed"
|
||||
});
|
||||
@@ -188,12 +188,7 @@ class KnowledgeBaseQueryTool(FunctionTool[AstrAgentContext]):
|
||||
@dataclass
|
||||
class SendMessageToUserTool(FunctionTool[AstrAgentContext]):
|
||||
name: str = "send_message_to_user"
|
||||
description: str = (
|
||||
"Send message to the user. "
|
||||
"Supports various message types including `plain`, `image`, `record`, `video`, `file`, and `mention_user`. "
|
||||
"Use this tool to send media files (`image`, `record`, `video`, `file`), "
|
||||
"or when you need to proactively message the user(such as cron job). For normal text replies, you can output directly."
|
||||
)
|
||||
description: str = "Directly send message to the user. Only use this tool when you need to proactively message the user. Otherwise you can directly output the reply in the conversation."
|
||||
|
||||
parameters: dict = Field(
|
||||
default_factory=lambda: {
|
||||
|
||||
@@ -164,10 +164,7 @@ class CreateSkillPayloadTool(NeoSkillToolBase):
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"payload": {
|
||||
"anyOf": [
|
||||
{"type": "object"},
|
||||
{"type": "array", "items": {"type": "object"}},
|
||||
],
|
||||
"anyOf": [{"type": "object"}, {"type": "array"}],
|
||||
"description": (
|
||||
"Skill payload JSON. Typical schema: {skill_markdown, inputs, outputs, meta}. "
|
||||
"This only stores content and returns payload_ref; it does not create a candidate or release."
|
||||
|
||||
@@ -1132,18 +1132,6 @@ CONFIG_METADATA_2 = {
|
||||
"proxy": "",
|
||||
"custom_headers": {},
|
||||
},
|
||||
"MiniMax": {
|
||||
"id": "minimax",
|
||||
"provider": "minimax",
|
||||
"type": "openai_chat_completion",
|
||||
"provider_type": "chat_completion",
|
||||
"enable": True,
|
||||
"key": [],
|
||||
"api_base": "https://api.minimaxi.com/v1",
|
||||
"timeout": 120,
|
||||
"proxy": "",
|
||||
"custom_headers": {},
|
||||
},
|
||||
"xAI": {
|
||||
"id": "xai",
|
||||
"provider": "xai",
|
||||
|
||||
@@ -391,47 +391,6 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
else:
|
||||
msg.append(File(name=filename, file=url, url=url))
|
||||
|
||||
@staticmethod
|
||||
def _parse_face_message(content: str) -> str:
|
||||
"""Parse QQ official face message format and convert to readable text.
|
||||
|
||||
QQ official face message format:
|
||||
<faceType=4,faceId="",ext="eyJ0ZXh0IjoiW+a7oeWktOmXruWPt10ifQ==">
|
||||
|
||||
The ext field contains base64-encoded JSON with a 'text' field
|
||||
describing the emoji (e.g., '[满头问号]').
|
||||
|
||||
Args:
|
||||
content: The message content that may contain face tags.
|
||||
|
||||
Returns:
|
||||
Content with face tags replaced by readable emoji descriptions.
|
||||
"""
|
||||
import base64
|
||||
import json
|
||||
import re
|
||||
|
||||
def replace_face(match):
|
||||
face_tag = match.group(0)
|
||||
# Extract ext field from the face tag
|
||||
ext_match = re.search(r'ext="([^"]*)"', face_tag)
|
||||
if ext_match:
|
||||
try:
|
||||
ext_encoded = ext_match.group(1)
|
||||
# Decode base64 and parse JSON
|
||||
ext_decoded = base64.b64decode(ext_encoded).decode("utf-8")
|
||||
ext_data = json.loads(ext_decoded)
|
||||
emoji_text = ext_data.get("text", "")
|
||||
if emoji_text:
|
||||
return f"[表情:{emoji_text}]"
|
||||
except Exception:
|
||||
pass
|
||||
# Fallback if parsing fails
|
||||
return "[表情]"
|
||||
|
||||
# Match face tags: <faceType=...>
|
||||
return re.sub(r"<faceType=\d+[^>]*>", replace_face, content)
|
||||
|
||||
@staticmethod
|
||||
def _parse_from_qqofficial(
|
||||
message: botpy.message.Message
|
||||
@@ -457,10 +416,7 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
abm.group_id = message.group_openid
|
||||
else:
|
||||
abm.sender = MessageMember(message.author.user_openid, "")
|
||||
# Parse face messages to readable text
|
||||
abm.message_str = QQOfficialPlatformAdapter._parse_face_message(
|
||||
message.content.strip()
|
||||
)
|
||||
abm.message_str = message.content.strip()
|
||||
abm.self_id = "unknown_selfid"
|
||||
msg.append(At(qq="qq_official"))
|
||||
msg.append(Plain(abm.message_str))
|
||||
@@ -476,12 +432,10 @@ class QQOfficialPlatformAdapter(Platform):
|
||||
else:
|
||||
abm.self_id = ""
|
||||
|
||||
plain_content = QQOfficialPlatformAdapter._parse_face_message(
|
||||
message.content.replace(
|
||||
"<@!" + str(abm.self_id) + ">",
|
||||
"",
|
||||
).strip()
|
||||
)
|
||||
plain_content = message.content.replace(
|
||||
"<@!" + str(abm.self_id) + ">",
|
||||
"",
|
||||
).strip()
|
||||
|
||||
QQOfficialPlatformAdapter._append_attachments(msg, message.attachments)
|
||||
abm.message = msg
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
import asyncio
|
||||
import logging
|
||||
import time
|
||||
from typing import cast
|
||||
|
||||
import quart
|
||||
@@ -40,9 +39,6 @@ class QQOfficialWebhook:
|
||||
self.client = botpy_client
|
||||
self.event_queue = event_queue
|
||||
self.shutdown_event = asyncio.Event()
|
||||
# Deduplication cache for webhook retry callbacks.
|
||||
self._seen_event_ids: dict[str, float] = {}
|
||||
self._dedup_ttl: int = 60 # seconds
|
||||
|
||||
async def initialize(self) -> None:
|
||||
logger.info("正在登录到 QQ 官方机器人...")
|
||||
@@ -110,22 +106,6 @@ class QQOfficialWebhook:
|
||||
print(signed)
|
||||
return signed
|
||||
|
||||
event_id = msg.get("id")
|
||||
if event_id:
|
||||
now = time.monotonic()
|
||||
# Lazily evict expired entries to prevent unbounded growth.
|
||||
expired = [
|
||||
k
|
||||
for k, ts in self._seen_event_ids.items()
|
||||
if now - ts > self._dedup_ttl
|
||||
]
|
||||
for k in expired:
|
||||
del self._seen_event_ids[k]
|
||||
if event_id in self._seen_event_ids:
|
||||
logger.debug(f"Duplicate webhook event {event_id!r}, skipping.")
|
||||
return {"opcode": 12}
|
||||
self._seen_event_ids[event_id] = now
|
||||
|
||||
if event and opcode == BotWebSocket.WS_DISPATCH_EVENT:
|
||||
event = msg["t"].lower()
|
||||
try:
|
||||
|
||||
@@ -25,16 +25,6 @@ from astrbot.api.platform import AstrBotMessage, MessageType, PlatformMetadata
|
||||
from astrbot.core.utils.metrics import Metric
|
||||
|
||||
|
||||
def _is_gif(path: str) -> bool:
|
||||
if path.lower().endswith(".gif"):
|
||||
return True
|
||||
try:
|
||||
with open(path, "rb") as f:
|
||||
return f.read(6) in (b"GIF87a", b"GIF89a")
|
||||
except OSError:
|
||||
return False
|
||||
|
||||
|
||||
class TelegramPlatformEvent(AstrMessageEvent):
|
||||
# Telegram 的最大消息长度限制
|
||||
MAX_MESSAGE_LENGTH = 4096
|
||||
@@ -301,13 +291,7 @@ class TelegramPlatformEvent(AstrMessageEvent):
|
||||
await client.send_message(text=chunk, **cast(Any, payload))
|
||||
elif isinstance(i, Image):
|
||||
image_path = await i.convert_to_file_path()
|
||||
if _is_gif(image_path):
|
||||
send_coro = client.send_animation
|
||||
media_kwarg = {"animation": image_path}
|
||||
else:
|
||||
send_coro = client.send_photo
|
||||
media_kwarg = {"photo": image_path}
|
||||
await send_coro(**media_kwarg, **cast(Any, payload))
|
||||
await client.send_photo(photo=image_path, **cast(Any, payload))
|
||||
elif isinstance(i, File):
|
||||
path = await i.get_file()
|
||||
name = i.name or os.path.basename(path)
|
||||
@@ -422,20 +406,12 @@ class TelegramPlatformEvent(AstrMessageEvent):
|
||||
on_text(i.text)
|
||||
elif isinstance(i, Image):
|
||||
image_path = await i.convert_to_file_path()
|
||||
if _is_gif(image_path):
|
||||
action = ChatAction.UPLOAD_VIDEO
|
||||
send_coro = self.client.send_animation
|
||||
media_kwarg = {"animation": image_path}
|
||||
else:
|
||||
action = ChatAction.UPLOAD_PHOTO
|
||||
send_coro = self.client.send_photo
|
||||
media_kwarg = {"photo": image_path}
|
||||
await self._send_media_with_action(
|
||||
self.client,
|
||||
action,
|
||||
send_coro,
|
||||
ChatAction.UPLOAD_PHOTO,
|
||||
self.client.send_photo,
|
||||
user_name=user_name,
|
||||
**media_kwarg,
|
||||
photo=image_path,
|
||||
**cast(Any, payload),
|
||||
)
|
||||
elif isinstance(i, File):
|
||||
|
||||
@@ -440,16 +440,9 @@ class WecomAIBotAdapter(Platform):
|
||||
)
|
||||
|
||||
def _extract_session_id(self, message_data: dict[str, Any]) -> str:
|
||||
"""从消息数据中提取会话ID
|
||||
群聊使用 chatid,单聊使用 userid
|
||||
"""
|
||||
chattype = message_data.get("chattype", "single")
|
||||
if chattype == "group":
|
||||
chat_id = message_data.get("chatid", "default_group")
|
||||
return format_session_id("wecomai", chat_id)
|
||||
else:
|
||||
user_id = message_data.get("from", {}).get("userid", "default_user")
|
||||
return format_session_id("wecomai", user_id)
|
||||
"""从消息数据中提取会话ID"""
|
||||
user_id = message_data.get("from", {}).get("userid", "default_user")
|
||||
return format_session_id("wecomai", user_id)
|
||||
|
||||
async def _enqueue_message(
|
||||
self,
|
||||
|
||||
@@ -808,8 +808,6 @@ class ProviderManager:
|
||||
config.save_config()
|
||||
# load instance
|
||||
await self.load_provider(new_config)
|
||||
# sync in-memory config for API queries (e.g., embedding provider list)
|
||||
self.providers_config = astrbot_config["provider"]
|
||||
|
||||
async def terminate(self) -> None:
|
||||
if self._mcp_init_task and not self._mcp_init_task.done():
|
||||
|
||||
@@ -13,11 +13,3 @@ class ProviderGroq(ProviderOpenAIOfficial):
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.reasoning_key = "reasoning"
|
||||
|
||||
def _finally_convert_payload(self, payloads: dict) -> None:
|
||||
"""Groq rejects assistant history items that include reasoning_content."""
|
||||
super()._finally_convert_payload(payloads)
|
||||
for message in payloads.get("messages", []):
|
||||
if message.get("role") == "assistant":
|
||||
message.pop("reasoning_content", None)
|
||||
message.pop("reasoning", None)
|
||||
|
||||
@@ -40,46 +40,25 @@ class OpenAIEmbeddingProvider(EmbeddingProvider):
|
||||
|
||||
async def get_embedding(self, text: str) -> list[float]:
|
||||
"""获取文本的嵌入"""
|
||||
kwargs = self._embedding_kwargs()
|
||||
embedding = await self.client.embeddings.create(
|
||||
input=text,
|
||||
model=self.model,
|
||||
**kwargs,
|
||||
dimensions=self.get_dim(),
|
||||
)
|
||||
return embedding.data[0].embedding
|
||||
|
||||
async def get_embeddings(self, text: list[str]) -> list[list[float]]:
|
||||
"""批量获取文本的嵌入"""
|
||||
kwargs = self._embedding_kwargs()
|
||||
embeddings = await self.client.embeddings.create(
|
||||
input=text,
|
||||
model=self.model,
|
||||
**kwargs,
|
||||
dimensions=self.get_dim(),
|
||||
)
|
||||
return [item.embedding for item in embeddings.data]
|
||||
|
||||
def _embedding_kwargs(self) -> dict:
|
||||
"""构建嵌入请求的可选参数"""
|
||||
kwargs = {}
|
||||
if "embedding_dimensions" in self.provider_config:
|
||||
try:
|
||||
kwargs["dimensions"] = int(self.provider_config["embedding_dimensions"])
|
||||
except (ValueError, TypeError):
|
||||
logger.warning(
|
||||
f"embedding_dimensions in embedding configs is not a valid integer: '{self.provider_config['embedding_dimensions']}', ignored."
|
||||
)
|
||||
return kwargs
|
||||
|
||||
def get_dim(self) -> int:
|
||||
"""获取向量的维度"""
|
||||
if "embedding_dimensions" in self.provider_config:
|
||||
try:
|
||||
return int(self.provider_config["embedding_dimensions"])
|
||||
except (ValueError, TypeError):
|
||||
logger.warning(
|
||||
f"embedding_dimensions in embedding configs is not a valid integer: '{self.provider_config['embedding_dimensions']}', ignored."
|
||||
)
|
||||
return 0
|
||||
return int(self.provider_config.get("embedding_dimensions", 1024))
|
||||
|
||||
async def terminate(self):
|
||||
if self.client:
|
||||
|
||||
@@ -311,7 +311,7 @@ class ProviderOpenAIOfficial(Provider):
|
||||
state.handle_chunk(chunk)
|
||||
except Exception as e:
|
||||
logger.warning("Saving chunk state error: " + str(e))
|
||||
if not chunk.choices:
|
||||
if len(chunk.choices) == 0:
|
||||
continue
|
||||
delta = chunk.choices[0].delta
|
||||
# logger.debug(f"chunk delta: {delta}")
|
||||
@@ -322,7 +322,7 @@ class ProviderOpenAIOfficial(Provider):
|
||||
if reasoning:
|
||||
llm_response.reasoning_content = reasoning
|
||||
_y = True
|
||||
if delta and delta.content:
|
||||
if delta.content:
|
||||
# Don't strip streaming chunks to preserve spaces between words
|
||||
completion_text = self._normalize_content(delta.content, strip=False)
|
||||
llm_response.result_chain = MessageChain(
|
||||
@@ -345,7 +345,7 @@ class ProviderOpenAIOfficial(Provider):
|
||||
) -> str:
|
||||
"""Extract reasoning content from OpenAI ChatCompletion if available."""
|
||||
reasoning_text = ""
|
||||
if not completion.choices:
|
||||
if len(completion.choices) == 0:
|
||||
return reasoning_text
|
||||
if isinstance(completion, ChatCompletion):
|
||||
choice = completion.choices[0]
|
||||
@@ -468,7 +468,7 @@ class ProviderOpenAIOfficial(Provider):
|
||||
"""Parse OpenAI ChatCompletion into LLMResponse"""
|
||||
llm_response = LLMResponse("assistant")
|
||||
|
||||
if not completion.choices:
|
||||
if len(completion.choices) == 0:
|
||||
raise Exception("API 返回的 completion 为空。")
|
||||
choice = completion.choices[0]
|
||||
|
||||
|
||||
@@ -25,22 +25,12 @@ class UmopConfigRouter:
|
||||
)
|
||||
self.umop_to_conf_id = sp_data
|
||||
|
||||
@staticmethod
|
||||
def _split_umo(umo: str) -> tuple[str, str, str] | None:
|
||||
"""将 UMO 拆分为 3 个部分,同时保留 session_id 中的 ':'"""
|
||||
if not isinstance(umo, str):
|
||||
return None
|
||||
parts = umo.split(":", 2)
|
||||
if len(parts) != 3:
|
||||
return None
|
||||
return parts[0], parts[1], parts[2]
|
||||
|
||||
def _is_umo_match(self, p1: str, p2: str) -> bool:
|
||||
"""判断 p2 umo 是否逻辑包含于 p1 umo"""
|
||||
p1_ls = self._split_umo(p1)
|
||||
p2_ls = self._split_umo(p2)
|
||||
p1_ls = p1.split(":")
|
||||
p2_ls = p2.split(":")
|
||||
|
||||
if p1_ls is None or p2_ls is None:
|
||||
if len(p1_ls) != 3 or len(p2_ls) != 3:
|
||||
return False # 非法格式
|
||||
|
||||
return all(p == "" or fnmatch.fnmatchcase(t, p) for p, t in zip(p1_ls, p2_ls))
|
||||
@@ -72,7 +62,7 @@ class UmopConfigRouter:
|
||||
|
||||
"""
|
||||
for part in new_routing:
|
||||
if self._split_umo(part) is None:
|
||||
if not isinstance(part, str) or len(part.split(":")) != 3:
|
||||
raise ValueError(
|
||||
"umop keys must be strings in the format [platform_id]:[message_type]:[session_id], with optional wildcards * or empty for all",
|
||||
)
|
||||
@@ -91,7 +81,7 @@ class UmopConfigRouter:
|
||||
ValueError: 如果 umo 格式不正确
|
||||
|
||||
"""
|
||||
if self._split_umo(umo) is None:
|
||||
if not isinstance(umo, str) or len(umo.split(":")) != 3:
|
||||
raise ValueError(
|
||||
"umop must be a string in the format [platform_id]:[message_type]:[session_id], with optional wildcards * or empty for all",
|
||||
)
|
||||
@@ -109,7 +99,7 @@ class UmopConfigRouter:
|
||||
ValueError: 当 umo 格式不正确时抛出
|
||||
"""
|
||||
|
||||
if self._split_umo(umo) is None:
|
||||
if not isinstance(umo, str) or len(umo.split(":")) != 3:
|
||||
raise ValueError(
|
||||
"umop must be a string in the format [platform_id]:[message_type]:[session_id], with optional wildcards * or empty for all",
|
||||
)
|
||||
|
||||
@@ -36,20 +36,6 @@ async def track_conversation(convs: dict, conv_id: str):
|
||||
convs.pop(conv_id, None)
|
||||
|
||||
|
||||
async def _poll_webchat_stream_result(back_queue, username: str):
|
||||
try:
|
||||
result = await asyncio.wait_for(back_queue.get(), timeout=1)
|
||||
except asyncio.TimeoutError:
|
||||
return None, False
|
||||
except asyncio.CancelledError:
|
||||
logger.debug(f"[WebChat] 用户 {username} 断开聊天长连接。")
|
||||
return None, True
|
||||
except Exception as e:
|
||||
logger.error(f"WebChat stream error: {e}")
|
||||
return None, False
|
||||
return result, False
|
||||
|
||||
|
||||
class ChatRoute(Route):
|
||||
def __init__(
|
||||
self,
|
||||
@@ -357,12 +343,16 @@ class ChatRoute(Route):
|
||||
|
||||
async with track_conversation(self.running_convs, webchat_conv_id):
|
||||
while True:
|
||||
result, should_break = await _poll_webchat_stream_result(
|
||||
back_queue, username
|
||||
)
|
||||
if should_break:
|
||||
try:
|
||||
result = await asyncio.wait_for(back_queue.get(), timeout=1)
|
||||
except asyncio.TimeoutError:
|
||||
continue
|
||||
except asyncio.CancelledError:
|
||||
logger.debug(f"[WebChat] 用户 {username} 断开聊天长连接。")
|
||||
client_disconnected = True
|
||||
break
|
||||
except Exception as e:
|
||||
logger.error(f"WebChat stream error: {e}")
|
||||
|
||||
if not result:
|
||||
continue
|
||||
|
||||
|
||||
@@ -36,6 +36,7 @@
|
||||
"remixicon": "3.5.0",
|
||||
"shiki": "^3.20.0",
|
||||
"stream-markdown": "^0.0.13",
|
||||
"stream-monaco": "^0.0.17",
|
||||
"vee-validate": "4.11.3",
|
||||
"vite-plugin-vuetify": "2.1.3",
|
||||
"vue": "3.3.4",
|
||||
|
||||
Generated
+4
-4
@@ -81,6 +81,9 @@ importers:
|
||||
stream-markdown:
|
||||
specifier: ^0.0.13
|
||||
version: 0.0.13(shiki@3.22.0)
|
||||
stream-monaco:
|
||||
specifier: ^0.0.17
|
||||
version: 0.0.17(monaco-editor@0.52.2)
|
||||
vee-validate:
|
||||
specifier: 4.11.3
|
||||
version: 4.11.3(vue@3.3.4)
|
||||
@@ -3297,7 +3300,6 @@ snapshots:
|
||||
'@shikijs/core': 3.22.0
|
||||
'@shikijs/types': 3.22.0
|
||||
'@shikijs/vscode-textmate': 10.0.2
|
||||
optional: true
|
||||
|
||||
'@shikijs/themes@3.22.0':
|
||||
dependencies:
|
||||
@@ -3990,8 +3992,7 @@ snapshots:
|
||||
json-schema-traverse: 1.0.0
|
||||
require-from-string: 2.0.2
|
||||
|
||||
alien-signals@2.0.8:
|
||||
optional: true
|
||||
alien-signals@2.0.8: {}
|
||||
|
||||
ansi-regex@5.0.1: {}
|
||||
|
||||
@@ -5442,7 +5443,6 @@ snapshots:
|
||||
alien-signals: 2.0.8
|
||||
monaco-editor: 0.52.2
|
||||
shiki: 3.22.0
|
||||
optional: true
|
||||
|
||||
stringify-entities@4.0.4:
|
||||
dependencies:
|
||||
|
||||
@@ -74,7 +74,7 @@
|
||||
:stagedImagesUrl="stagedImagesUrl"
|
||||
:stagedAudioUrl="stagedAudioUrl"
|
||||
:stagedFiles="stagedNonImageFiles"
|
||||
:disabled="false"
|
||||
:disabled="isStreaming"
|
||||
:is-running="isStreaming || isConvRunning"
|
||||
:enableStreaming="enableStreaming"
|
||||
:isRecording="isRecording"
|
||||
@@ -106,7 +106,7 @@
|
||||
:stagedImagesUrl="stagedImagesUrl"
|
||||
:stagedAudioUrl="stagedAudioUrl"
|
||||
:stagedFiles="stagedNonImageFiles"
|
||||
:disabled="false"
|
||||
:disabled="isStreaming"
|
||||
:is-running="isStreaming || isConvRunning"
|
||||
:enableStreaming="enableStreaming"
|
||||
:isRecording="isRecording"
|
||||
@@ -137,7 +137,7 @@
|
||||
:stagedImagesUrl="stagedImagesUrl"
|
||||
:stagedAudioUrl="stagedAudioUrl"
|
||||
:stagedFiles="stagedNonImageFiles"
|
||||
:disabled="false"
|
||||
:disabled="isStreaming"
|
||||
:is-running="isStreaming || isConvRunning"
|
||||
:enableStreaming="enableStreaming"
|
||||
:isRecording="isRecording"
|
||||
@@ -348,12 +348,6 @@ function setSendShortcut(mode: SendShortcut) {
|
||||
localStorage.setItem(SEND_SHORTCUT_STORAGE_KEY, mode);
|
||||
}
|
||||
|
||||
function focusChatInput() {
|
||||
nextTick(() => {
|
||||
chatInputRef.value?.focusInput?.();
|
||||
});
|
||||
}
|
||||
|
||||
// 检测是否为手机端
|
||||
function checkMobile() {
|
||||
isMobile.value = window.innerWidth <= 768;
|
||||
@@ -511,7 +505,6 @@ async function handleSelectConversation(sessionIds: string[]) {
|
||||
nextTick(() => {
|
||||
messageList.value?.scrollToBottom();
|
||||
});
|
||||
focusChatInput();
|
||||
}
|
||||
|
||||
function handleNewChat() {
|
||||
@@ -521,7 +514,6 @@ function handleNewChat() {
|
||||
// 退出项目视图
|
||||
selectedProjectId.value = null;
|
||||
projectSessions.value = [];
|
||||
focusChatInput();
|
||||
}
|
||||
|
||||
async function handleDeleteConversation(sessionId: string) {
|
||||
@@ -679,11 +671,6 @@ async function handleSendMessage() {
|
||||
const selectedProviderId = selection?.providerId || '';
|
||||
const selectedModelName = selection?.modelName || '';
|
||||
|
||||
// 点击发送后立即将消息区滚到底部,确保用户看到最新消息
|
||||
nextTick(() => {
|
||||
messageList.value?.scrollToBottom();
|
||||
});
|
||||
|
||||
await sendMsg(
|
||||
promptToSend,
|
||||
filesToSend,
|
||||
@@ -693,11 +680,6 @@ async function handleSendMessage() {
|
||||
replyToSend
|
||||
);
|
||||
|
||||
// 发送流程结束后再兜底一次,处理异步渲染场景
|
||||
nextTick(() => {
|
||||
messageList.value?.scrollToBottom();
|
||||
});
|
||||
|
||||
// 如果在项目中创建了新会话,将其添加到项目
|
||||
if (isCreatingNewSession && currentProjectId && currSessionId.value) {
|
||||
await addSessionToProject(currSessionId.value, currentProjectId);
|
||||
|
||||
@@ -95,7 +95,7 @@
|
||||
{{ isRecording ? tm('voice.speaking') : tm('voice.startRecording') }}
|
||||
</v-tooltip>
|
||||
</v-btn>
|
||||
<v-btn icon v-if="isRunning && !canSend" @click="$emit('stop')" variant="tonal" color="primary" class="send-btn">
|
||||
<v-btn icon v-if="isRunning" @click="$emit('stop')" variant="tonal" color="primary" class="send-btn">
|
||||
<v-icon icon="mdi-stop" variant="text" plain></v-icon>
|
||||
<v-tooltip activator="parent" location="top">
|
||||
{{ tm('input.stopGenerating') }}
|
||||
@@ -373,11 +373,6 @@ function getCurrentSelection() {
|
||||
return providerModelMenuRef.value?.getCurrentSelection();
|
||||
}
|
||||
|
||||
function focusInput() {
|
||||
if (!inputField.value) return;
|
||||
inputField.value.focus();
|
||||
}
|
||||
|
||||
onMounted(() => {
|
||||
if (inputField.value) {
|
||||
inputField.value.addEventListener('paste', handlePaste);
|
||||
@@ -393,8 +388,7 @@ onBeforeUnmount(() => {
|
||||
});
|
||||
|
||||
defineExpose({
|
||||
getCurrentSelection,
|
||||
focusInput
|
||||
getCurrentSelection
|
||||
});
|
||||
</script>
|
||||
|
||||
|
||||
@@ -180,7 +180,7 @@
|
||||
|
||||
<script>
|
||||
import { useI18n, useModuleI18n } from '@/i18n/composables';
|
||||
import { enableKatex, enableMermaid, MarkdownCodeBlockNode, setCustomComponents } from 'markstream-vue'
|
||||
import { enableKatex, enableMermaid, setCustomComponents } from 'markstream-vue'
|
||||
import 'markstream-vue/index.css'
|
||||
import 'katex/dist/katex.min.css'
|
||||
import 'highlight.js/styles/github.css';
|
||||
@@ -194,11 +194,8 @@ import ActionRef from './message_list_comps/ActionRef.vue';
|
||||
enableKatex();
|
||||
enableMermaid();
|
||||
|
||||
// 注册 message-list 专用组件:引用节点 + Shiki 代码块渲染
|
||||
setCustomComponents('message-list', {
|
||||
ref: RefNode,
|
||||
code_block: MarkdownCodeBlockNode
|
||||
});
|
||||
// 注册自定义 ref 组件
|
||||
setCustomComponents('message-list', { ref: RefNode });
|
||||
|
||||
export default {
|
||||
name: 'MessageList',
|
||||
|
||||
@@ -22,7 +22,7 @@
|
||||
v-model:prompt="prompt"
|
||||
:stagedImagesUrl="stagedImagesUrl"
|
||||
:stagedAudioUrl="stagedAudioUrl"
|
||||
:disabled="false"
|
||||
:disabled="isStreaming"
|
||||
:is-running="isStreaming || isConvRunning"
|
||||
:enableStreaming="enableStreaming"
|
||||
:isRecording="isRecording"
|
||||
|
||||
@@ -63,9 +63,8 @@
|
||||
<!-- Text (Markdown) -->
|
||||
<MarkdownRender
|
||||
v-else-if="renderPart.part.type === 'plain' && renderPart.part.text && renderPart.part.text.trim()"
|
||||
:key="`${renderPart.key}-${isDark ? 'dark' : 'light'}`"
|
||||
custom-id="message-list" :custom-html-tags="['ref']" :content="renderPart.part.text" :typewriter="false"
|
||||
class="markdown-content" :is-dark="isDark" />
|
||||
class="markdown-content" :is-dark="isDark" :monacoOptions="{ theme: isDark ? 'vs-dark' : 'vs-light' }" />
|
||||
|
||||
<!-- Image -->
|
||||
<div v-else-if="renderPart.part.type === 'image' && renderPart.part.embedded_url" class="embedded-images">
|
||||
|
||||
@@ -9,7 +9,7 @@
|
||||
</span>
|
||||
</div>
|
||||
<div v-if="isExpanded" class="reasoning-content animate-fade-in">
|
||||
<MarkdownRender :key="`reasoning-${isDark ? 'dark' : 'light'}`" :content="reasoning" class="reasoning-text markdown-content"
|
||||
<MarkdownRender :content="reasoning" class="reasoning-text markdown-content"
|
||||
:typewriter="false" :is-dark="isDark" :style="isDark ? { opacity: '0.85' } : {}" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -9,33 +9,33 @@
|
||||
*/
|
||||
export function getProviderIcon(type) {
|
||||
const icons = {
|
||||
'openai': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/openai.svg',
|
||||
'azure': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/azure.svg',
|
||||
'xai': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/xai.svg',
|
||||
'anthropic': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/anthropic.svg',
|
||||
'ollama': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/ollama.svg',
|
||||
'google': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/gemini-color.svg',
|
||||
'deepseek': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/deepseek.svg',
|
||||
'modelscope': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/modelscope.svg',
|
||||
'zhipu': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/zhipu.svg',
|
||||
'nvidia': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/nvidia-color.svg',
|
||||
'siliconflow': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/siliconcloud.svg',
|
||||
'moonshot': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/kimi.svg',
|
||||
'ppio': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/ppio.svg',
|
||||
'dify': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/dify-color.svg',
|
||||
"coze": "https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@1.66.0/icons/coze.svg",
|
||||
'dashscope': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/alibabacloud-color.svg',
|
||||
'openai': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/openai.svg',
|
||||
'azure': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/azure.svg',
|
||||
'xai': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/xai.svg',
|
||||
'anthropic': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/anthropic.svg',
|
||||
'ollama': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/ollama.svg',
|
||||
'google': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/gemini-color.svg',
|
||||
'deepseek': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/deepseek.svg',
|
||||
'modelscope': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/modelscope.svg',
|
||||
'zhipu': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/zhipu.svg',
|
||||
'nvidia': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/nvidia-color.svg',
|
||||
'siliconflow': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/siliconcloud.svg',
|
||||
'moonshot': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/kimi.svg',
|
||||
'ppio': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/ppio.svg',
|
||||
'dify': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/dify-color.svg',
|
||||
"coze": "https://registry.npmmirror.com/@lobehub/icons-static-svg/1.66.0/files/icons/coze.svg",
|
||||
'dashscope': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/alibabacloud-color.svg',
|
||||
'deerflow': 'https://cdn.jsdelivr.net/gh/bytedance/deer-flow@main/frontend/public/images/deer.svg',
|
||||
'fastgpt': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/fastgpt-color.svg',
|
||||
'lm_studio': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/lmstudio.svg',
|
||||
'fishaudio': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/fishaudio.svg',
|
||||
'minimax': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/minimax.svg',
|
||||
'302ai': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@1.53.0/icons/ai302-color.svg',
|
||||
'microsoft': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/microsoft.svg',
|
||||
'vllm': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/vllm.svg',
|
||||
'groq': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/groq.svg',
|
||||
'aihubmix': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/aihubmix-color.svg',
|
||||
'openrouter': 'https://cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@latest/icons/openrouter.svg',
|
||||
'fastgpt': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/fastgpt-color.svg',
|
||||
'lm_studio': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/lmstudio.svg',
|
||||
'fishaudio': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/fishaudio.svg',
|
||||
'minimax': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/minimax.svg',
|
||||
'302ai': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/1.53.0/files/icons/ai302-color.svg',
|
||||
'microsoft': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/microsoft.svg',
|
||||
'vllm': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/vllm.svg',
|
||||
'groq': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/groq.svg',
|
||||
'aihubmix': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/aihubmix-color.svg',
|
||||
'openrouter': 'https://registry.npmmirror.com/@lobehub/icons-static-svg/latest/files/icons/openrouter.svg',
|
||||
"tokenpony": "https://tokenpony.cn/tokenpony-web/logo.png",
|
||||
"compshare": "https://compshare.cn/favicon.ico"
|
||||
};
|
||||
|
||||
@@ -6,7 +6,7 @@ This documentation may not cover all features comprehensively. If you have any q
|
||||
|
||||
### Discord
|
||||
|
||||
<https://discord.gg/hAVk6tgV36>
|
||||
<https://discord.gg/PxgzhmxJ>
|
||||
|
||||
### GitHub
|
||||
|
||||
|
||||
@@ -21,7 +21,7 @@
|
||||
|
||||
### Discord
|
||||
|
||||
https://discord.gg/hAVk6tgV36
|
||||
https://discord.gg/PxgzhmxJ
|
||||
|
||||
### Astrbook
|
||||
|
||||
|
||||
@@ -13,5 +13,5 @@
|
||||
```bash
|
||||
uv tool install astrbot
|
||||
astrbot init # 只需要在第一次部署时执行,后续启动不需要执行
|
||||
astrbot run
|
||||
astrbot
|
||||
```
|
||||
|
||||
@@ -41,4 +41,4 @@ AstrBot 已经上架至雨云的预装软件列表,支持**一键安装** Astr
|
||||
|
||||
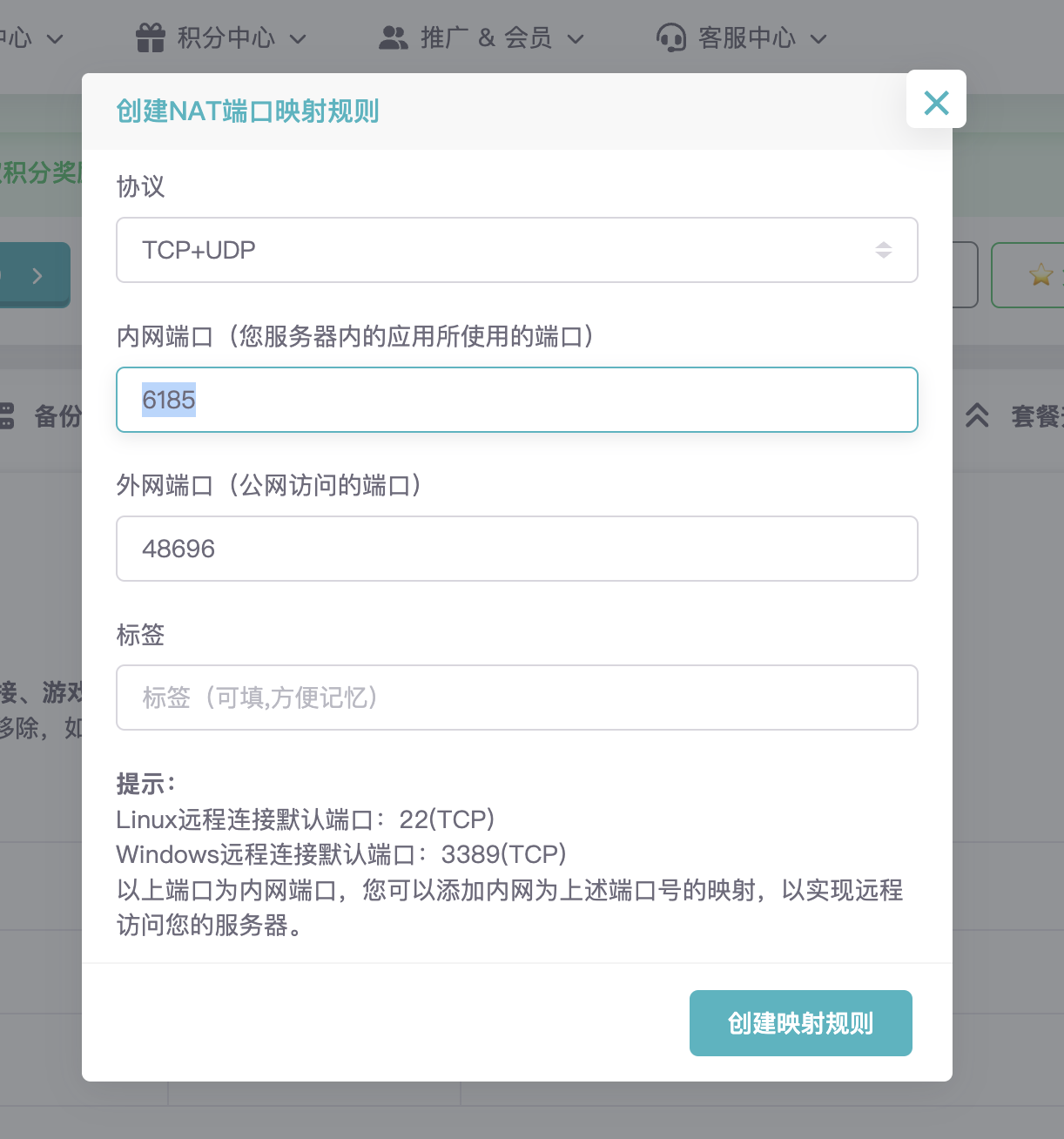
|
||||
|
||||
然后,内网端口填写 `6185`,点击 `创建映射规则`,这样就可以通过 `http://IP:上面设置好的外网端口` 访问 AstrBot 的管理面板了。如果无法打开,请点击`备用地址`,通过备用地址访问管理面板。
|
||||
然后,内网端口填写 `6185`,点击 `创建映射规则`,这样就可以通过 `http://IP:上面设置好的外网端口` 访问 AstrBot 的管理面板了。
|
||||
|
||||
@@ -23,7 +23,7 @@ AstrBot 是一个开源的一站式 Agentic 个人和群聊助手,可在 QQ、
|
||||
|
||||
- 部署 AstrBot:阅读部署指南,快速在本地机器或云服务器上部署 AstrBot。
|
||||
- 连接 IM 平台:按照说明将 AstrBot 连接到您喜欢的 IM 平台,如 Discord、Telegram、Slack 等。
|
||||
- 配置 AI 模型:AstrBot 支持各种 AI 模型。请参阅 [连接模型服务](/providers/start)
|
||||
- 配置 AI 模型:AstrBot 支持各种 AI 模型。请参阅 [连接模型服务](/config/providers/start)
|
||||
|
||||
## 它是如何实现的?
|
||||
|
||||
|
||||
Executable
+253
@@ -0,0 +1,253 @@
|
||||
#!/usr/bin/env python3
|
||||
"""
|
||||
Auto-generate changelog from git commits using LLM.
|
||||
Usage: python scripts/generate_changelog.py [--version VERSION]
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import re
|
||||
import subprocess
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def get_latest_tag():
|
||||
"""Get the latest git tag."""
|
||||
result = subprocess.run(
|
||||
["git", "describe", "--tags", "--abbrev=0"],
|
||||
capture_output=True,
|
||||
text=True,
|
||||
check=True,
|
||||
)
|
||||
return result.stdout.strip()
|
||||
|
||||
|
||||
def get_commits_since_tag(tag):
|
||||
"""Get all commit messages since the specified tag."""
|
||||
result = subprocess.run(
|
||||
["git", "log", f"{tag}..HEAD", "--pretty=format:%H|%s|%b"],
|
||||
capture_output=True,
|
||||
text=True,
|
||||
check=True,
|
||||
)
|
||||
commits = []
|
||||
for line in result.stdout.strip().split("\n"):
|
||||
if not line:
|
||||
continue
|
||||
parts = line.split("|", 2)
|
||||
if len(parts) >= 2:
|
||||
commit_hash = parts[0]
|
||||
subject = parts[1]
|
||||
body = parts[2] if len(parts) > 2 else ""
|
||||
commits.append({"hash": commit_hash[:7], "subject": subject, "body": body})
|
||||
return commits
|
||||
|
||||
|
||||
def extract_issue_number(text):
|
||||
"""Extract issue number from commit message."""
|
||||
# Match #1234 or (#1234)
|
||||
match = re.search(r"#(\d+)", text)
|
||||
return match.group(1) if match else None
|
||||
|
||||
|
||||
def call_llm_for_changelog(commits, version):
|
||||
"""Call LLM to generate changelog from commits."""
|
||||
try:
|
||||
# Try to use OpenAI API or other LLM providers
|
||||
import openai
|
||||
|
||||
# Build prompt
|
||||
commits_text = "\n".join([f"- {c['subject']}" for c in commits])
|
||||
|
||||
prompt = f"""Based on the following git commit messages, generate a changelog document in BOTH Chinese and English.
|
||||
|
||||
Commit messages:
|
||||
{commits_text}
|
||||
|
||||
Please organize the changes into these categories:
|
||||
- 新增 (New Features)
|
||||
- 修复 (Bug Fixes)
|
||||
- 优化 (Improvements)
|
||||
- 其他 (Others)
|
||||
|
||||
Format requirements:
|
||||
1. Start with Chinese version under "## What's Changed"
|
||||
2. Follow with English version under "## What's Changed (EN)"
|
||||
3. Use markdown format with proper bullet points
|
||||
4. Keep descriptions concise and user-friendly
|
||||
5. If a commit mentions an issue number (#1234), include it in the format ([#1234](https://github.com/AstrBotDevs/AstrBot/issues/1234))
|
||||
|
||||
Example format:
|
||||
## What's Changed
|
||||
|
||||
### 新增
|
||||
- 支持某某功能 ([#1234](https://github.com/AstrBotDevs/AstrBot/issues/1234))
|
||||
|
||||
### 修复
|
||||
- 修复某某问题
|
||||
|
||||
## What's Changed (EN)
|
||||
|
||||
### New Features
|
||||
- Add support for something ([#1234](https://github.com/AstrBotDevs/AstrBot/issues/1234))
|
||||
|
||||
### Bug Fixes
|
||||
- Fix something
|
||||
"""
|
||||
|
||||
client = openai.OpenAI(
|
||||
api_key=os.getenv("OPENAI_API_KEY"),
|
||||
base_url=os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1"),
|
||||
)
|
||||
|
||||
response = client.chat.completions.create(
|
||||
model=os.getenv("OPENAI_MODEL", "gpt-4"),
|
||||
messages=[
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a helpful assistant that generates well-structured changelogs.",
|
||||
},
|
||||
{"role": "user", "content": prompt},
|
||||
],
|
||||
temperature=0.3,
|
||||
)
|
||||
|
||||
return response.choices[0].message.content
|
||||
|
||||
except ImportError:
|
||||
print(
|
||||
"Warning: openai package not installed. Install it with: pip install openai"
|
||||
)
|
||||
return generate_simple_changelog(commits)
|
||||
except Exception as e:
|
||||
print(f"Warning: Failed to call LLM API: {e}")
|
||||
print("Falling back to simple changelog generation...")
|
||||
return generate_simple_changelog(commits)
|
||||
|
||||
|
||||
def generate_simple_changelog(commits):
|
||||
"""Generate a simple changelog without LLM."""
|
||||
sections = {
|
||||
"feat": ("新增", "New Features", []),
|
||||
"fix": ("修复", "Bug Fixes", []),
|
||||
"perf": ("优化", "Improvements", []),
|
||||
"docs": ("文档", "Documentation", []),
|
||||
"refactor": ("重构", "Refactoring", []),
|
||||
"test": ("测试", "Tests", []),
|
||||
"chore": ("其他", "Chore", []),
|
||||
"other": ("其他", "Others", []),
|
||||
}
|
||||
|
||||
# Categorize commits by conventional commit type
|
||||
for commit in commits:
|
||||
subject = commit["subject"]
|
||||
issue_num = extract_issue_number(subject)
|
||||
issue_link = (
|
||||
f" ([#{issue_num}](https://github.com/AstrBotDevs/AstrBot/issues/{issue_num}))"
|
||||
if issue_num
|
||||
else ""
|
||||
)
|
||||
|
||||
# Detect conventional commit type
|
||||
matched = False
|
||||
for prefix in ["feat", "fix", "perf", "docs", "refactor", "test", "chore"]:
|
||||
if subject.lower().startswith(f"{prefix}:") or subject.lower().startswith(
|
||||
f"{prefix}("
|
||||
):
|
||||
# Remove prefix for display
|
||||
clean_subject = re.sub(
|
||||
r"^[a-z]+(\([^)]+\))?:\s*", "", subject, flags=re.IGNORECASE
|
||||
)
|
||||
sections[prefix][2].append(f"- {clean_subject}{issue_link}")
|
||||
matched = True
|
||||
break
|
||||
|
||||
if not matched:
|
||||
sections["other"][2].append(f"- {subject}{issue_link}")
|
||||
|
||||
# Build Chinese version
|
||||
changelog_zh = "## What's Changed\n\n"
|
||||
for section_key in ["feat", "fix", "perf", "docs", "refactor", "test", "other"]:
|
||||
zh_title, _, items = sections[section_key]
|
||||
if items:
|
||||
changelog_zh += f"### {zh_title}\n\n"
|
||||
changelog_zh += "\n".join(items) + "\n\n"
|
||||
|
||||
# Build English version
|
||||
changelog_en = "## What's Changed (EN)\n\n"
|
||||
for section_key in ["feat", "fix", "perf", "docs", "refactor", "test", "other"]:
|
||||
_, en_title, items = sections[section_key]
|
||||
if items:
|
||||
changelog_en += f"### {en_title}\n\n"
|
||||
changelog_en += "\n".join(items) + "\n\n"
|
||||
|
||||
return changelog_zh + changelog_en
|
||||
|
||||
|
||||
def main() -> None:
|
||||
parser = argparse.ArgumentParser(description="Generate changelog from git commits")
|
||||
parser.add_argument(
|
||||
"--version", help="Version number for the changelog (e.g., v4.13.3)"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use-llm",
|
||||
action="store_true",
|
||||
help="Use LLM to generate changelog (requires OpenAI API key)",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
# Get latest tag
|
||||
try:
|
||||
latest_tag = get_latest_tag()
|
||||
print(f"Latest tag: {latest_tag}")
|
||||
except subprocess.CalledProcessError:
|
||||
print("Error: No tags found in repository")
|
||||
sys.exit(1)
|
||||
|
||||
# Get commits since tag
|
||||
commits = get_commits_since_tag(latest_tag)
|
||||
if not commits:
|
||||
print(f"No commits found since {latest_tag}")
|
||||
sys.exit(0)
|
||||
|
||||
print(f"Found {len(commits)} commits since {latest_tag}")
|
||||
|
||||
# Determine version
|
||||
if args.version:
|
||||
version = args.version
|
||||
else:
|
||||
# Auto-increment patch version
|
||||
match = re.match(r"v(\d+)\.(\d+)\.(\d+)", latest_tag)
|
||||
if match:
|
||||
major, minor, patch = map(int, match.groups())
|
||||
version = f"v{major}.{minor}.{patch + 1}"
|
||||
else:
|
||||
print(f"Warning: Could not parse version from tag {latest_tag}")
|
||||
version = "vX.X.X"
|
||||
|
||||
print(f"Generating changelog for {version}...")
|
||||
|
||||
# Generate changelog
|
||||
if args.use_llm:
|
||||
changelog_content = call_llm_for_changelog(commits, version)
|
||||
else:
|
||||
changelog_content = generate_simple_changelog(commits)
|
||||
|
||||
# Save to file
|
||||
changelog_dir = Path(__file__).parent.parent / "changelogs"
|
||||
changelog_dir.mkdir(exist_ok=True)
|
||||
changelog_file = changelog_dir / f"{version}.md"
|
||||
|
||||
with open(changelog_file, "w", encoding="utf-8") as f:
|
||||
f.write(changelog_content)
|
||||
|
||||
print(f"\n✓ Changelog generated: {changelog_file}")
|
||||
print("\nPreview:")
|
||||
print("=" * 80)
|
||||
print(changelog_content)
|
||||
print("=" * 80)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -1,56 +0,0 @@
|
||||
import asyncio
|
||||
|
||||
import pytest
|
||||
|
||||
from astrbot.dashboard.routes.chat import _poll_webchat_stream_result
|
||||
|
||||
|
||||
class _QueueThatRaises:
|
||||
def __init__(self, exc: BaseException):
|
||||
self._exc = exc
|
||||
|
||||
async def get(self):
|
||||
raise self._exc
|
||||
|
||||
|
||||
class _QueueWithResult:
|
||||
def __init__(self, result):
|
||||
self._result = result
|
||||
|
||||
async def get(self):
|
||||
return self._result
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_poll_webchat_stream_result_breaks_on_cancelled_error():
|
||||
result, should_break = await _poll_webchat_stream_result(
|
||||
_QueueThatRaises(asyncio.CancelledError()),
|
||||
"alice",
|
||||
)
|
||||
|
||||
assert result is None
|
||||
assert should_break is True
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_poll_webchat_stream_result_continues_on_generic_exception():
|
||||
result, should_break = await _poll_webchat_stream_result(
|
||||
_QueueThatRaises(RuntimeError("boom")),
|
||||
"alice",
|
||||
)
|
||||
|
||||
assert result is None
|
||||
assert should_break is False
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_poll_webchat_stream_result_returns_queue_payload():
|
||||
payload = {"type": "end", "data": ""}
|
||||
|
||||
result, should_break = await _poll_webchat_stream_result(
|
||||
_QueueWithResult(payload),
|
||||
"alice",
|
||||
)
|
||||
|
||||
assert result == payload
|
||||
assert should_break is False
|
||||
@@ -2,7 +2,6 @@ from types import SimpleNamespace
|
||||
|
||||
import pytest
|
||||
|
||||
from astrbot.core.provider.sources.groq_source import ProviderGroq
|
||||
from astrbot.core.provider.sources.openai_source import ProviderOpenAIOfficial
|
||||
|
||||
|
||||
@@ -33,21 +32,6 @@ def _make_provider(overrides: dict | None = None) -> ProviderOpenAIOfficial:
|
||||
)
|
||||
|
||||
|
||||
def _make_groq_provider(overrides: dict | None = None) -> ProviderGroq:
|
||||
provider_config = {
|
||||
"id": "test-groq",
|
||||
"type": "groq_chat_completion",
|
||||
"model": "qwen/qwen3-32b",
|
||||
"key": ["test-key"],
|
||||
}
|
||||
if overrides:
|
||||
provider_config.update(overrides)
|
||||
return ProviderGroq(
|
||||
provider_config=provider_config,
|
||||
provider_settings={},
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_handle_api_error_content_moderated_removes_images():
|
||||
provider = _make_provider(
|
||||
@@ -214,57 +198,6 @@ def test_extract_error_text_candidates_truncates_long_response_text():
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_openai_payload_keeps_reasoning_content_in_assistant_history():
|
||||
provider = _make_provider()
|
||||
try:
|
||||
payloads = {
|
||||
"messages": [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": [
|
||||
{"type": "think", "think": "step 1"},
|
||||
{"type": "text", "text": "final answer"},
|
||||
],
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
provider._finally_convert_payload(payloads)
|
||||
|
||||
assistant_message = payloads["messages"][0]
|
||||
assert assistant_message["content"] == [{"type": "text", "text": "final answer"}]
|
||||
assert assistant_message["reasoning_content"] == "step 1"
|
||||
finally:
|
||||
await provider.terminate()
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_groq_payload_drops_reasoning_content_from_assistant_history():
|
||||
provider = _make_groq_provider()
|
||||
try:
|
||||
payloads = {
|
||||
"messages": [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": [
|
||||
{"type": "think", "think": "step 1"},
|
||||
{"type": "text", "text": "final answer"},
|
||||
],
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
provider._finally_convert_payload(payloads)
|
||||
|
||||
assistant_message = payloads["messages"][0]
|
||||
assert assistant_message["content"] == [{"type": "text", "text": "final answer"}]
|
||||
assert "reasoning_content" not in assistant_message
|
||||
assert "reasoning" not in assistant_message
|
||||
finally:
|
||||
await provider.terminate()
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_handle_api_error_content_moderated_without_images_raises():
|
||||
provider = _make_provider(
|
||||
|
||||
Reference in New Issue
Block a user