Compare commits
24 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
565c371e5c | ||
|
|
a1c9dc5d01 | ||
|
|
d3d4e1db7b | ||
|
|
78b3e12c66 | ||
|
|
c42ac87ee1 | ||
|
|
3fbd16b211 | ||
|
|
e77500ff69 | ||
|
|
2c49ac0dcf | ||
|
|
65decfbe87 | ||
|
|
92c31192de | ||
|
|
b795f804a7 | ||
|
|
bc3b5e58a4 | ||
|
|
7e3c32b828 | ||
|
|
ceb32dce9f | ||
|
|
84e880af5f | ||
|
|
9909d774ed | ||
|
|
6b3868b4be | ||
|
|
11c840953a | ||
|
|
2bbca887ce | ||
|
|
dd89a4b334 | ||
|
|
a3fa8a5a7c | ||
|
|
aa60467782 | ||
|
|
d936bb0a10 | ||
|
|
64e0183b55 |
@@ -21,7 +21,23 @@
|
||||
<!--If merged, your code will serve tens of thousands of users! Please double-check the following items before submitting.-->
|
||||
<!--如果分支被合并,您的代码将服务于数万名用户!在提交前,请核查一下几点内容。-->
|
||||
|
||||
- [ ] 😊 如果 PR 中有新加入的功能,已经通过 Issue / 邮件等方式和作者讨论过。/ If there are new features added in the PR, I have discussed it with the authors through issues/emails, etc.
|
||||
- [ ] 👀 我的更改经过了良好的测试,**并已在上方提供了“验证步骤”和“运行截图”**。/ My changes have been well-tested, **and "Verification Steps" and "Screenshots" have been provided above**.
|
||||
- [ ] 🤓 我确保没有引入新依赖库,或者引入了新依赖库的同时将其添加到了 `requirements.txt` 和 `pyproject.toml` 文件相应位置。/ I have ensured that no new dependencies are introduced, OR if new dependencies are introduced, they have been added to the appropriate locations in `requirements.txt` and `pyproject.toml`.
|
||||
- [ ] 😮 我的更改没有引入恶意代码。/ My changes do not introduce malicious code.
|
||||
- [ ] 😊 如果 PR 中有新加入的功能,已经通过 Issue / 邮件等方式和作者讨论过。
|
||||
/ If there are new features added in the PR, I have discussed it with the authors through issues/emails, etc.
|
||||
|
||||
- [ ] 👀 我的更改经过了良好的测试,**并已在上方提供了“验证步骤”和“运行截图”**。
|
||||
/ My changes have been well-tested, **and "Verification Steps" and "Screenshots" have been provided above**.
|
||||
|
||||
- [ ] 🤓 我确保没有引入新依赖库,或者引入了新依赖库的同时将其添加到 `requirements.txt` 和 `pyproject.toml` 文件相应位置。
|
||||
/ I have ensured that no new dependencies are introduced, OR if new dependencies are introduced, they have been added to the appropriate locations in `requirements.txt` and `pyproject.toml`.
|
||||
|
||||
- [ ] 😮 我的更改没有引入恶意代码。
|
||||
/ My changes do not introduce malicious code.
|
||||
|
||||
- [ ] ⚠️ 我已认真阅读并理解以上所有内容,确保本次提交符合规范。
|
||||
/ I have read and understood all the above and confirm this PR follows the rules.
|
||||
|
||||
- [ ] 🚀 我确保本次开发**基于 dev 分支**,并将代码合并至**开发分支**(除非极其紧急,才允许合并到主分支)。
|
||||
/ I confirm that this development is **based on the dev branch** and will be merged into the **development branch**, unless it is extremely urgent to merge into the main branch.
|
||||
|
||||
- [ ] ⚠️ 我**没有**认真阅读以上内容,直接提交。
|
||||
/ I **did not** read the above carefully before submitting.
|
||||
|
||||
@@ -0,0 +1,45 @@
|
||||
name: PR Checklist Check
|
||||
|
||||
on:
|
||||
pull_request_target:
|
||||
types: [opened, edited, reopened, synchronize]
|
||||
|
||||
jobs:
|
||||
check:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
permissions:
|
||||
pull-requests: write
|
||||
issues: write
|
||||
|
||||
steps:
|
||||
- name: Check checklist
|
||||
id: check
|
||||
uses: actions/github-script@v7
|
||||
with:
|
||||
script: |
|
||||
const body = context.payload.pull_request.body || "";
|
||||
const regex = /-\s*\[\s*x\s*\].*没有.*认真阅读/i;
|
||||
const bad = regex.test(body);
|
||||
core.setOutput("bad", bad);
|
||||
|
||||
- name: Close PR
|
||||
if: steps.check.outputs.bad == 'true'
|
||||
uses: actions/github-script@v7
|
||||
with:
|
||||
script: |
|
||||
const pr = context.payload.pull_request;
|
||||
|
||||
await github.rest.issues.createComment({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
issue_number: pr.number,
|
||||
body: `检测到你勾选了“我没有认真阅读”,PR 已关闭。`
|
||||
});
|
||||
|
||||
await github.rest.pulls.update({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
pull_number: pr.number,
|
||||
state: "closed"
|
||||
});
|
||||
@@ -326,6 +326,7 @@ async def run_live_agent(
|
||||
|
||||
# 创建队列
|
||||
text_queue: asyncio.Queue[str | None] = asyncio.Queue()
|
||||
delta_queue: asyncio.Queue[str | None] = asyncio.Queue()
|
||||
# audio_queue stored bytes or (text, bytes)
|
||||
audio_queue: asyncio.Queue[bytes | tuple[str, bytes] | None] = asyncio.Queue()
|
||||
|
||||
@@ -334,6 +335,7 @@ async def run_live_agent(
|
||||
_run_agent_feeder(
|
||||
agent_runner,
|
||||
text_queue,
|
||||
delta_queue,
|
||||
max_step,
|
||||
show_tool_use,
|
||||
show_tool_call_result,
|
||||
@@ -353,32 +355,63 @@ async def run_live_agent(
|
||||
|
||||
# 3. 主循环:从 audio_queue 读取音频并 yield
|
||||
try:
|
||||
while True:
|
||||
queue_item = await audio_queue.get()
|
||||
delta_done = False
|
||||
audio_done = False
|
||||
while not (delta_done and audio_done):
|
||||
task_sources: dict[asyncio.Task, str] = {}
|
||||
if not delta_done:
|
||||
task = asyncio.create_task(delta_queue.get())
|
||||
task_sources[task] = "delta"
|
||||
if not audio_done:
|
||||
task = asyncio.create_task(audio_queue.get())
|
||||
task_sources[task] = "audio"
|
||||
|
||||
if queue_item is None:
|
||||
break
|
||||
done, pending = await asyncio.wait(
|
||||
list(task_sources),
|
||||
return_when=asyncio.FIRST_COMPLETED,
|
||||
)
|
||||
|
||||
text = None
|
||||
if isinstance(queue_item, tuple):
|
||||
text, audio_data = queue_item
|
||||
else:
|
||||
audio_data = queue_item
|
||||
for task in pending:
|
||||
task.cancel()
|
||||
if pending:
|
||||
await asyncio.gather(*pending, return_exceptions=True)
|
||||
|
||||
if not first_chunk_received:
|
||||
# 记录首帧延迟(从开始处理到收到第一个音频块)
|
||||
tts_first_frame_time = time.time() - tts_start_time
|
||||
first_chunk_received = True
|
||||
for task in done:
|
||||
source = task_sources[task]
|
||||
queue_item = task.result()
|
||||
if source == "delta":
|
||||
if queue_item is None:
|
||||
delta_done = True
|
||||
continue
|
||||
yield MessageChain(
|
||||
chain=[Plain(queue_item)], type="live_text_delta"
|
||||
)
|
||||
continue
|
||||
|
||||
# 将音频数据封装为 MessageChain
|
||||
import base64
|
||||
if queue_item is None:
|
||||
audio_done = True
|
||||
continue
|
||||
|
||||
audio_b64 = base64.b64encode(audio_data).decode("utf-8")
|
||||
comps: list[BaseMessageComponent] = [Plain(audio_b64)]
|
||||
if text:
|
||||
comps.append(Json(data={"text": text}))
|
||||
chain = MessageChain(chain=comps, type="audio_chunk")
|
||||
yield chain
|
||||
text = None
|
||||
if isinstance(queue_item, tuple):
|
||||
text, audio_data = queue_item
|
||||
else:
|
||||
audio_data = queue_item
|
||||
|
||||
if not first_chunk_received:
|
||||
# 记录首帧延迟(从开始处理到收到第一个音频块)
|
||||
tts_first_frame_time = time.time() - tts_start_time
|
||||
first_chunk_received = True
|
||||
|
||||
# 将音频数据封装为 MessageChain
|
||||
import base64
|
||||
|
||||
audio_b64 = base64.b64encode(audio_data).decode("utf-8")
|
||||
comps: list[BaseMessageComponent] = [Plain(audio_b64)]
|
||||
if text:
|
||||
comps.append(Json(data={"text": text}))
|
||||
chain = MessageChain(chain=comps, type="audio_chunk")
|
||||
yield chain
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"[Live Agent] 运行时发生错误: {e}", exc_info=True)
|
||||
@@ -421,6 +454,7 @@ async def run_live_agent(
|
||||
async def _run_agent_feeder(
|
||||
agent_runner: AgentRunner,
|
||||
text_queue: asyncio.Queue,
|
||||
delta_queue: asyncio.Queue,
|
||||
max_step: int,
|
||||
show_tool_use: bool,
|
||||
show_tool_call_result: bool,
|
||||
@@ -440,9 +474,13 @@ async def _run_agent_feeder(
|
||||
if chain is None:
|
||||
continue
|
||||
|
||||
if chain.type == "reasoning":
|
||||
continue
|
||||
|
||||
# 提取文本
|
||||
text = chain.get_plain_text()
|
||||
if text:
|
||||
await delta_queue.put(text)
|
||||
buffer += text
|
||||
|
||||
# 分句逻辑:匹配标点符号
|
||||
@@ -477,6 +515,7 @@ async def _run_agent_feeder(
|
||||
finally:
|
||||
# 发送结束信号
|
||||
await text_queue.put(None)
|
||||
await delta_queue.put(None)
|
||||
|
||||
|
||||
async def _safe_tts_stream_wrapper(
|
||||
|
||||
@@ -440,9 +440,16 @@ class WecomAIBotAdapter(Platform):
|
||||
)
|
||||
|
||||
def _extract_session_id(self, message_data: dict[str, Any]) -> str:
|
||||
"""从消息数据中提取会话ID"""
|
||||
user_id = message_data.get("from", {}).get("userid", "default_user")
|
||||
return format_session_id("wecomai", user_id)
|
||||
"""从消息数据中提取会话ID
|
||||
群聊使用 chatid,单聊使用 userid
|
||||
"""
|
||||
chattype = message_data.get("chattype", "single")
|
||||
if chattype == "group":
|
||||
chat_id = message_data.get("chatid", "default_group")
|
||||
return format_session_id("wecomai", chat_id)
|
||||
else:
|
||||
user_id = message_data.get("from", {}).get("userid", "default_user")
|
||||
return format_session_id("wecomai", user_id)
|
||||
|
||||
async def _enqueue_message(
|
||||
self,
|
||||
|
||||
@@ -808,6 +808,8 @@ class ProviderManager:
|
||||
config.save_config()
|
||||
# load instance
|
||||
await self.load_provider(new_config)
|
||||
# sync in-memory config for API queries (e.g., embedding provider list)
|
||||
self.providers_config = astrbot_config["provider"]
|
||||
|
||||
async def terminate(self) -> None:
|
||||
if self._mcp_init_task and not self._mcp_init_task.done():
|
||||
|
||||
@@ -13,3 +13,11 @@ class ProviderGroq(ProviderOpenAIOfficial):
|
||||
) -> None:
|
||||
super().__init__(provider_config, provider_settings)
|
||||
self.reasoning_key = "reasoning"
|
||||
|
||||
def _finally_convert_payload(self, payloads: dict) -> None:
|
||||
"""Groq rejects assistant history items that include reasoning_content."""
|
||||
super()._finally_convert_payload(payloads)
|
||||
for message in payloads.get("messages", []):
|
||||
if message.get("role") == "assistant":
|
||||
message.pop("reasoning_content", None)
|
||||
message.pop("reasoning", None)
|
||||
|
||||
@@ -16,4 +16,7 @@ class ProviderOpenRouter(ProviderOpenAIOfficial):
|
||||
self.client._custom_headers["HTTP-Referer"] = ( # type: ignore
|
||||
"https://github.com/AstrBotDevs/AstrBot"
|
||||
)
|
||||
self.client._custom_headers["X-TITLE"] = "AstrBot" # type: ignore
|
||||
self.client._custom_headers["X-OpenRouter-Title"] = "AstrBot" # type: ignore
|
||||
self.client._custom_headers["X-OpenRouter-Categories"] = (
|
||||
"general-chat,personal-agent" # type: ignore
|
||||
)
|
||||
|
||||
@@ -25,12 +25,22 @@ class UmopConfigRouter:
|
||||
)
|
||||
self.umop_to_conf_id = sp_data
|
||||
|
||||
@staticmethod
|
||||
def _split_umo(umo: str) -> tuple[str, str, str] | None:
|
||||
"""将 UMO 拆分为 3 个部分,同时保留 session_id 中的 ':'"""
|
||||
if not isinstance(umo, str):
|
||||
return None
|
||||
parts = umo.split(":", 2)
|
||||
if len(parts) != 3:
|
||||
return None
|
||||
return parts[0], parts[1], parts[2]
|
||||
|
||||
def _is_umo_match(self, p1: str, p2: str) -> bool:
|
||||
"""判断 p2 umo 是否逻辑包含于 p1 umo"""
|
||||
p1_ls = p1.split(":")
|
||||
p2_ls = p2.split(":")
|
||||
p1_ls = self._split_umo(p1)
|
||||
p2_ls = self._split_umo(p2)
|
||||
|
||||
if len(p1_ls) != 3 or len(p2_ls) != 3:
|
||||
if p1_ls is None or p2_ls is None:
|
||||
return False # 非法格式
|
||||
|
||||
return all(p == "" or fnmatch.fnmatchcase(t, p) for p, t in zip(p1_ls, p2_ls))
|
||||
@@ -62,7 +72,7 @@ class UmopConfigRouter:
|
||||
|
||||
"""
|
||||
for part in new_routing:
|
||||
if not isinstance(part, str) or len(part.split(":")) != 3:
|
||||
if self._split_umo(part) is None:
|
||||
raise ValueError(
|
||||
"umop keys must be strings in the format [platform_id]:[message_type]:[session_id], with optional wildcards * or empty for all",
|
||||
)
|
||||
@@ -81,7 +91,7 @@ class UmopConfigRouter:
|
||||
ValueError: 如果 umo 格式不正确
|
||||
|
||||
"""
|
||||
if not isinstance(umo, str) or len(umo.split(":")) != 3:
|
||||
if self._split_umo(umo) is None:
|
||||
raise ValueError(
|
||||
"umop must be a string in the format [platform_id]:[message_type]:[session_id], with optional wildcards * or empty for all",
|
||||
)
|
||||
@@ -99,7 +109,7 @@ class UmopConfigRouter:
|
||||
ValueError: 当 umo 格式不正确时抛出
|
||||
"""
|
||||
|
||||
if not isinstance(umo, str) or len(umo.split(":")) != 3:
|
||||
if self._split_umo(umo) is None:
|
||||
raise ValueError(
|
||||
"umop must be a string in the format [platform_id]:[message_type]:[session_id], with optional wildcards * or empty for all",
|
||||
)
|
||||
|
||||
@@ -130,16 +130,6 @@ class LiveChatRoute(Route):
|
||||
|
||||
async def live_chat_ws(self) -> None:
|
||||
"""Legacy Live Chat WebSocket 处理器(默认 ct=live)"""
|
||||
await self._unified_ws_loop(force_ct="live")
|
||||
|
||||
async def unified_chat_ws(self) -> None:
|
||||
"""Unified Chat WebSocket 处理器(支持 ct=live/chat)"""
|
||||
await self._unified_ws_loop(force_ct=None)
|
||||
|
||||
async def _unified_ws_loop(self, force_ct: str | None = None) -> None:
|
||||
"""统一 WebSocket 循环"""
|
||||
# WebSocket 不能通过 header 传递 token,需要从 query 参数获取
|
||||
# 注意:WebSocket 上下文使用 websocket.args 而不是 request.args
|
||||
token = websocket.args.get("token")
|
||||
if not token:
|
||||
await websocket.close(1008, "Missing authentication token")
|
||||
@@ -156,6 +146,49 @@ class LiveChatRoute(Route):
|
||||
await websocket.close(1008, "Invalid token")
|
||||
return
|
||||
|
||||
await self.run_ws_session(username=username, force_ct="live")
|
||||
|
||||
async def unified_chat_ws(self) -> None:
|
||||
"""Unified Chat WebSocket 处理器(支持 ct=live/chat)"""
|
||||
token = websocket.args.get("token")
|
||||
if not token:
|
||||
await websocket.close(1008, "Missing authentication token")
|
||||
return
|
||||
|
||||
try:
|
||||
jwt_secret = self.config["dashboard"].get("jwt_secret")
|
||||
payload = jwt.decode(token, jwt_secret, algorithms=["HS256"])
|
||||
username = payload["username"]
|
||||
except jwt.ExpiredSignatureError:
|
||||
await websocket.close(1008, "Token expired")
|
||||
return
|
||||
except jwt.InvalidTokenError:
|
||||
await websocket.close(1008, "Invalid token")
|
||||
return
|
||||
|
||||
await self.run_ws_session(username=username, force_ct=None)
|
||||
|
||||
async def _unified_ws_loop(self, force_ct: str | None = None) -> None:
|
||||
"""统一 WebSocket 循环"""
|
||||
# Keep the legacy entry point for internal call sites.
|
||||
token = websocket.args.get("token")
|
||||
if not token:
|
||||
await websocket.close(1008, "Missing authentication token")
|
||||
return
|
||||
try:
|
||||
jwt_secret = self.config["dashboard"].get("jwt_secret")
|
||||
payload = jwt.decode(token, jwt_secret, algorithms=["HS256"])
|
||||
username = payload["username"]
|
||||
except jwt.ExpiredSignatureError:
|
||||
await websocket.close(1008, "Token expired")
|
||||
return
|
||||
except jwt.InvalidTokenError:
|
||||
await websocket.close(1008, "Invalid token")
|
||||
return
|
||||
await self.run_ws_session(username=username, force_ct=force_ct)
|
||||
|
||||
async def run_ws_session(self, username: str, force_ct: str | None = None) -> None:
|
||||
"""Run a live/unified websocket session for an authenticated username."""
|
||||
session_id = f"webchat_live!{username}!{uuid.uuid4()}"
|
||||
live_session = LiveChatSession(session_id, username)
|
||||
self.sessions[session_id] = live_session
|
||||
@@ -690,6 +723,16 @@ class LiveChatRoute(Route):
|
||||
|
||||
elif msg_type == "end_speaking":
|
||||
# 结束说话
|
||||
if session.is_processing:
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "error",
|
||||
"data": "Session is busy",
|
||||
"code": "PROCESSING_ERROR",
|
||||
}
|
||||
)
|
||||
return
|
||||
|
||||
stamp = message.get("stamp")
|
||||
if not stamp:
|
||||
logger.warning("[Live Chat] end_speaking 缺少 stamp")
|
||||
@@ -703,45 +746,59 @@ class LiveChatRoute(Route):
|
||||
# 处理音频:STT -> LLM -> TTS
|
||||
await self._process_audio(session, audio_path, assemble_duration)
|
||||
|
||||
elif msg_type == "text_input":
|
||||
if session.is_processing:
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "error",
|
||||
"data": "Session is busy",
|
||||
"code": "PROCESSING_ERROR",
|
||||
}
|
||||
)
|
||||
return
|
||||
|
||||
user_text = message.get("text")
|
||||
if not isinstance(user_text, str):
|
||||
user_text = message.get("message")
|
||||
|
||||
if not isinstance(user_text, str) or not user_text.strip():
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "error",
|
||||
"data": "message must be non-empty text",
|
||||
"code": "INVALID_MESSAGE_FORMAT",
|
||||
}
|
||||
)
|
||||
return
|
||||
|
||||
await self._process_live_user_text(
|
||||
session,
|
||||
user_text=user_text.strip(),
|
||||
initial_metrics={"input_type": "text"},
|
||||
processing_start_time=time.time(),
|
||||
)
|
||||
|
||||
elif msg_type == "interrupt":
|
||||
# 用户打断
|
||||
session.should_interrupt = True
|
||||
logger.info(f"[Live Chat] 用户打断: {session.username}")
|
||||
|
||||
async def _process_audio(
|
||||
self, session: LiveChatSession, audio_path: str, assemble_duration: float
|
||||
async def _process_live_user_text(
|
||||
self,
|
||||
session: LiveChatSession,
|
||||
user_text: str,
|
||||
initial_metrics: dict[str, Any] | None = None,
|
||||
processing_start_time: float | None = None,
|
||||
) -> None:
|
||||
"""处理音频:STT -> LLM -> 流式 TTS"""
|
||||
"""处理 Live 用户文本:走 run_live_agent pipeline 并回传流式 TTS."""
|
||||
try:
|
||||
# 发送 WAV 组装耗时
|
||||
await websocket.send_json(
|
||||
{"t": "metrics", "data": {"wav_assemble_time": assemble_duration}}
|
||||
)
|
||||
wav_assembly_finish_time = time.time()
|
||||
if initial_metrics:
|
||||
await websocket.send_json({"t": "metrics", "data": initial_metrics})
|
||||
|
||||
processing_start = processing_start_time or time.time()
|
||||
session.is_processing = True
|
||||
session.should_interrupt = False
|
||||
|
||||
# 1. STT - 语音转文字
|
||||
ctx = self.plugin_manager.context
|
||||
stt_provider = ctx.provider_manager.stt_provider_insts[0]
|
||||
|
||||
if not stt_provider:
|
||||
logger.error("[Live Chat] STT Provider 未配置")
|
||||
await websocket.send_json({"t": "error", "data": "语音识别服务未配置"})
|
||||
return
|
||||
|
||||
await websocket.send_json(
|
||||
{"t": "metrics", "data": {"stt": stt_provider.meta().type}}
|
||||
)
|
||||
|
||||
user_text = await stt_provider.get_text(audio_path)
|
||||
if not user_text:
|
||||
logger.warning("[Live Chat] STT 识别结果为空")
|
||||
return
|
||||
|
||||
logger.info(f"[Live Chat] STT 结果: {user_text}")
|
||||
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "user_msg",
|
||||
@@ -761,7 +818,6 @@ class LiveChatRoute(Route):
|
||||
"action_type": "live", # 标记为 live mode
|
||||
}
|
||||
|
||||
# 将消息放入队列
|
||||
await queue.put((session.username, cid, payload))
|
||||
|
||||
# 3. 等待响应并流式发送 TTS 音频
|
||||
@@ -776,11 +832,9 @@ class LiveChatRoute(Route):
|
||||
# 用户打断,停止处理
|
||||
logger.info("[Live Chat] 检测到用户打断")
|
||||
await websocket.send_json({"t": "stop_play"})
|
||||
# 保存消息并标记为被打断
|
||||
await self._save_interrupted_message(
|
||||
session, user_text, bot_text
|
||||
)
|
||||
# 清空队列中未处理的消息
|
||||
while not back_queue.empty():
|
||||
try:
|
||||
back_queue.get_nowait()
|
||||
@@ -805,6 +859,7 @@ class LiveChatRoute(Route):
|
||||
|
||||
result_type = result.get("type")
|
||||
result_chain_type = result.get("chain_type")
|
||||
result_streaming = bool(result.get("streaming", False))
|
||||
data = result.get("data", "")
|
||||
|
||||
if result_chain_type == "agent_stats":
|
||||
@@ -827,29 +882,41 @@ class LiveChatRoute(Route):
|
||||
if result_chain_type == "tts_stats":
|
||||
try:
|
||||
stats = json.loads(data)
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "metrics",
|
||||
"data": stats,
|
||||
}
|
||||
)
|
||||
await websocket.send_json({"t": "metrics", "data": stats})
|
||||
except Exception as e:
|
||||
logger.error(f"[Live Chat] 解析 TTSStats 失败: {e}")
|
||||
continue
|
||||
|
||||
if result_chain_type == "live_text_delta":
|
||||
if data:
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "bot_delta_chunk",
|
||||
"data": {"text": data},
|
||||
}
|
||||
)
|
||||
continue
|
||||
|
||||
if result_type == "plain":
|
||||
# 普通文本消息
|
||||
if (
|
||||
result_streaming
|
||||
and data
|
||||
and result_chain_type != "reasoning"
|
||||
):
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "bot_delta_chunk",
|
||||
"data": {"text": data},
|
||||
}
|
||||
)
|
||||
bot_text += data
|
||||
|
||||
elif result_type == "audio_chunk":
|
||||
# 流式音频数据
|
||||
if not audio_playing:
|
||||
audio_playing = True
|
||||
logger.debug("[Live Chat] 开始播放音频流")
|
||||
|
||||
# Calculate latency from wav assembly finish to first audio chunk
|
||||
speak_to_first_frame_latency = (
|
||||
time.time() - wav_assembly_finish_time
|
||||
time.time() - processing_start
|
||||
)
|
||||
await websocket.send_json(
|
||||
{
|
||||
@@ -869,19 +936,15 @@ class LiveChatRoute(Route):
|
||||
}
|
||||
)
|
||||
|
||||
# 发送音频数据给前端
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "response",
|
||||
"data": data, # base64 编码的音频数据
|
||||
"data": data,
|
||||
}
|
||||
)
|
||||
|
||||
elif result_type in ["complete", "end"]:
|
||||
# 处理完成
|
||||
logger.info(f"[Live Chat] Bot 回复完成: {bot_text}")
|
||||
|
||||
# 如果没有音频流,发送 bot 消息文本
|
||||
if not audio_playing:
|
||||
await websocket.send_json(
|
||||
{
|
||||
@@ -893,11 +956,8 @@ class LiveChatRoute(Route):
|
||||
}
|
||||
)
|
||||
|
||||
# 发送结束标记
|
||||
await websocket.send_json({"t": "end"})
|
||||
|
||||
# 发送总耗时
|
||||
wav_to_tts_duration = time.time() - wav_assembly_finish_time
|
||||
wav_to_tts_duration = time.time() - processing_start
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "metrics",
|
||||
@@ -909,13 +969,65 @@ class LiveChatRoute(Route):
|
||||
webchat_queue_mgr.remove_back_queue(message_id)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"[Live Chat] 处理音频失败: {e}", exc_info=True)
|
||||
logger.error(f"[Live Chat] 处理文本失败: {e}", exc_info=True)
|
||||
await websocket.send_json({"t": "error", "data": f"处理失败: {str(e)}"})
|
||||
|
||||
finally:
|
||||
session.is_processing = False
|
||||
session.should_interrupt = False
|
||||
|
||||
async def _process_audio(
|
||||
self, session: LiveChatSession, audio_path: str, assemble_duration: float
|
||||
) -> None:
|
||||
"""处理音频:STT -> LLM -> 流式 TTS"""
|
||||
try:
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "metrics",
|
||||
"data": {
|
||||
"wav_assemble_time": assemble_duration,
|
||||
"input_type": "audio",
|
||||
},
|
||||
}
|
||||
)
|
||||
wav_assembly_finish_time = time.time()
|
||||
|
||||
# 1. STT - 语音转文字
|
||||
ctx = self.plugin_manager.context
|
||||
stt_provider = ctx.provider_manager.stt_provider_insts[0]
|
||||
|
||||
if not stt_provider:
|
||||
logger.error("[Live Chat] STT Provider 未配置")
|
||||
await websocket.send_json({"t": "error", "data": "语音识别服务未配置"})
|
||||
return
|
||||
|
||||
await websocket.send_json(
|
||||
{
|
||||
"t": "metrics",
|
||||
"data": {
|
||||
"stt": stt_provider.meta().type,
|
||||
},
|
||||
}
|
||||
)
|
||||
|
||||
user_text = await stt_provider.get_text(audio_path)
|
||||
if not user_text:
|
||||
logger.warning("[Live Chat] STT 识别结果为空")
|
||||
return
|
||||
|
||||
logger.info(f"[Live Chat] STT 结果: {user_text}")
|
||||
|
||||
await self._process_live_user_text(
|
||||
session,
|
||||
user_text=user_text,
|
||||
initial_metrics=None,
|
||||
processing_start_time=wav_assembly_finish_time,
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"[Live Chat] 处理音频失败: {e}", exc_info=True)
|
||||
await websocket.send_json({"t": "error", "data": f"处理失败: {str(e)}"})
|
||||
|
||||
async def _save_interrupted_message(
|
||||
self, session: LiveChatSession, user_text: str, bot_text: str
|
||||
) -> None:
|
||||
|
||||
@@ -19,6 +19,7 @@ from astrbot.core.utils.datetime_utils import to_utc_isoformat
|
||||
|
||||
from .api_key import ALL_OPEN_API_SCOPES
|
||||
from .chat import ChatRoute
|
||||
from .live_chat import LiveChatRoute
|
||||
from .route import Response, Route, RouteContext
|
||||
|
||||
|
||||
@@ -29,12 +30,14 @@ class OpenApiRoute(Route):
|
||||
db: BaseDatabase,
|
||||
core_lifecycle: AstrBotCoreLifecycle,
|
||||
chat_route: ChatRoute,
|
||||
live_chat_route: LiveChatRoute,
|
||||
) -> None:
|
||||
super().__init__(context)
|
||||
self.db = db
|
||||
self.core_lifecycle = core_lifecycle
|
||||
self.platform_manager = core_lifecycle.platform_manager
|
||||
self.chat_route = chat_route
|
||||
self.live_chat_route = live_chat_route
|
||||
|
||||
self.routes = {
|
||||
"/v1/chat": ("POST", self.chat_send),
|
||||
@@ -46,6 +49,7 @@ class OpenApiRoute(Route):
|
||||
}
|
||||
self.register_routes()
|
||||
self.app.websocket("/api/v1/chat/ws")(self.chat_ws)
|
||||
self.app.websocket("/api/v1/live/ws")(self.live_ws)
|
||||
|
||||
@staticmethod
|
||||
def _resolve_open_username(
|
||||
@@ -534,6 +538,39 @@ class OpenApiRoute(Route):
|
||||
except Exception as e:
|
||||
logger.debug("Open API WS connection closed: %s", e)
|
||||
|
||||
async def live_ws(self) -> None:
|
||||
authed, auth_err = await self._authenticate_chat_ws_api_key()
|
||||
if not authed:
|
||||
await self._send_chat_ws_error(auth_err or "Unauthorized", "UNAUTHORIZED")
|
||||
await websocket.close(1008, auth_err or "Unauthorized")
|
||||
return
|
||||
|
||||
username, username_err = self._resolve_open_username(
|
||||
websocket.args.get("username")
|
||||
)
|
||||
if username_err or not username:
|
||||
await self._send_chat_ws_error(
|
||||
username_err or "Invalid username",
|
||||
"BAD_USER",
|
||||
)
|
||||
await websocket.close(1008, username_err or "Invalid username")
|
||||
return
|
||||
|
||||
ct = websocket.args.get("ct")
|
||||
force_ct = ct.strip() if isinstance(ct, str) and ct.strip() else "live"
|
||||
if force_ct not in {"live", "chat"}:
|
||||
await self._send_chat_ws_error(
|
||||
"ct must be 'live' or 'chat'",
|
||||
"INVALID_MESSAGE",
|
||||
)
|
||||
await websocket.close(1008, "Invalid ct")
|
||||
return
|
||||
|
||||
await self.live_chat_route.run_ws_session(
|
||||
username=username,
|
||||
force_ct=force_ct,
|
||||
)
|
||||
|
||||
async def upload_file(self):
|
||||
return await self.chat_route.post_file()
|
||||
|
||||
|
||||
@@ -115,11 +115,13 @@ class AstrBotDashboard:
|
||||
self.ar = AuthRoute(self.context)
|
||||
self.api_key_route = ApiKeyRoute(self.context, db)
|
||||
self.chat_route = ChatRoute(self.context, db, core_lifecycle)
|
||||
self.live_chat_route = LiveChatRoute(self.context, db, core_lifecycle)
|
||||
self.open_api_route = OpenApiRoute(
|
||||
self.context,
|
||||
db,
|
||||
core_lifecycle,
|
||||
self.chat_route,
|
||||
self.live_chat_route,
|
||||
)
|
||||
self.chatui_project_route = ChatUIProjectRoute(self.context, db)
|
||||
self.tools_root = ToolsRoute(self.context, core_lifecycle)
|
||||
@@ -138,7 +140,6 @@ class AstrBotDashboard:
|
||||
self.kb_route = KnowledgeBaseRoute(self.context, core_lifecycle)
|
||||
self.platform_route = PlatformRoute(self.context, core_lifecycle)
|
||||
self.backup_route = BackupRoute(self.context, db, core_lifecycle)
|
||||
self.live_chat_route = LiveChatRoute(self.context, db, core_lifecycle)
|
||||
|
||||
self.app.add_url_rule(
|
||||
"/api/plug/<path:subpath>",
|
||||
@@ -244,6 +245,7 @@ class AstrBotDashboard:
|
||||
scope_map = {
|
||||
"/api/v1/chat": "chat",
|
||||
"/api/v1/chat/ws": "chat",
|
||||
"/api/v1/live/ws": "chat",
|
||||
"/api/v1/chat/sessions": "chat",
|
||||
"/api/v1/configs": "config",
|
||||
"/api/v1/file": "file",
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
+17
-3
@@ -98,14 +98,28 @@ axios.interceptors.request.use((config) => {
|
||||
// Some parts of the UI use fetch directly; without this, those requests will 401.
|
||||
const _origFetch = window.fetch.bind(window);
|
||||
window.fetch = (input: RequestInfo | URL, init?: RequestInit) => {
|
||||
const requestUrl = (() => {
|
||||
if (typeof input === 'string') return input;
|
||||
if (input instanceof URL) return input.toString();
|
||||
return input.url;
|
||||
})();
|
||||
|
||||
let shouldAttachAuth = false;
|
||||
try {
|
||||
const resolvedUrl = new URL(requestUrl, window.location.origin);
|
||||
shouldAttachAuth = resolvedUrl.origin === window.location.origin;
|
||||
} catch (_) {
|
||||
shouldAttachAuth = requestUrl.startsWith('/');
|
||||
}
|
||||
|
||||
const token = localStorage.getItem('token');
|
||||
if (!token) return _origFetch(input, init);
|
||||
const locale = localStorage.getItem('astrbot-locale');
|
||||
if (!token && !locale) return _origFetch(input, init);
|
||||
|
||||
const headers = new Headers(init?.headers || (typeof input !== 'string' && 'headers' in input ? (input as Request).headers : undefined));
|
||||
if (!headers.has('Authorization')) {
|
||||
if (shouldAttachAuth && token && !headers.has('Authorization')) {
|
||||
headers.set('Authorization', `Bearer ${token}`);
|
||||
}
|
||||
const locale = localStorage.getItem('astrbot-locale');
|
||||
if (locale && !headers.has('Accept-Language')) {
|
||||
headers.set('Accept-Language', locale);
|
||||
}
|
||||
|
||||
@@ -87,7 +87,13 @@ export default defineConfig({
|
||||
},
|
||||
{
|
||||
text: "OneBot v11",
|
||||
link: "/aiocqhttp"
|
||||
base: "/platform/aiocqhttp",
|
||||
collapsed: true,
|
||||
items: [
|
||||
{ text: "NapCat", link: "/napcat" },
|
||||
{ text: "Lagrange", link: "/lagrange" },
|
||||
{ text: "其他端", link: "/others" },
|
||||
],
|
||||
},
|
||||
{ text: "企微应用", link: "/wecom" },
|
||||
{ text: "企微智能机器人", link: "/wecom_ai_bot" },
|
||||
@@ -105,7 +111,7 @@ export default defineConfig({
|
||||
base: "/platform/satori",
|
||||
collapsed: true,
|
||||
items: [
|
||||
{ text: "接入 Satori", link: "/guide" },
|
||||
{ text: "使用 LLOneBot", link: "/llonebot" },
|
||||
{ text: "使用 server-satori", link: "/server-satori" },
|
||||
],
|
||||
},
|
||||
|
||||
@@ -29,6 +29,7 @@ X-API-Key: abk_xxx
|
||||
## Common Endpoints
|
||||
|
||||
- `POST /api/v1/chat`: send chat message (SSE stream, server generates UUID when `session_id` is omitted)
|
||||
- `GET /api/v1/live/ws`: Live API WebSocket (API Key auth, requires `username` query parameter, optional `ct=live|chat`)
|
||||
- `GET /api/v1/chat/sessions`: list sessions for a specific `username` with pagination
|
||||
- `GET /api/v1/configs`: list available config files
|
||||
- `POST /api/v1/file`: upload attachment
|
||||
@@ -49,3 +50,7 @@ curl -N 'http://localhost:6185/api/v1/chat' \
|
||||
Use the interactive docs:
|
||||
|
||||
- https://docs.astrbot.app/scalar.html
|
||||
|
||||
For the full Live API wire protocol, see:
|
||||
|
||||
- `docs/live-api/README.md`
|
||||
|
||||
@@ -0,0 +1,434 @@
|
||||
# AstrBot Live API Protocol
|
||||
|
||||
This document describes the current WebSocket protocol for AstrBot Live API.
|
||||
|
||||
## Endpoint
|
||||
|
||||
- Legacy JWT endpoint: `/api/live_chat/ws`
|
||||
- Legacy unified JWT endpoint: `/api/unified_chat/ws`
|
||||
- Open API endpoint: `/api/v1/live/ws`
|
||||
|
||||
## Authentication
|
||||
|
||||
### Legacy dashboard endpoints
|
||||
|
||||
Pass a dashboard JWT in the `token` query parameter.
|
||||
|
||||
Example:
|
||||
|
||||
```text
|
||||
ws://localhost:6185/api/live_chat/ws?token=<dashboard_jwt>
|
||||
```
|
||||
|
||||
### Open API endpoint
|
||||
|
||||
Use an API key and provide `username` in the query string.
|
||||
|
||||
Examples:
|
||||
|
||||
```text
|
||||
ws://localhost:6185/api/v1/live/ws?api_key=<api_key>&username=alice
|
||||
ws://localhost:6185/api/v1/live/ws?api_key=<api_key>&username=alice&ct=chat
|
||||
```
|
||||
|
||||
`ct` values:
|
||||
|
||||
- `live`: voice conversation mode
|
||||
- `chat`: unified chat mode over the same WebSocket transport
|
||||
|
||||
The Open API endpoint reuses the `chat` API key scope.
|
||||
|
||||
## Transport
|
||||
|
||||
- Protocol: WebSocket
|
||||
- Payload format: UTF-8 JSON text frames
|
||||
- Audio upload format in `live` mode:
|
||||
- client sends raw PCM frames encoded as Base64
|
||||
- sample rate: `16000`
|
||||
- channels: `1`
|
||||
- sample width: `16-bit`
|
||||
|
||||
## Top-Level Envelope
|
||||
|
||||
### Client to server
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "message_type",
|
||||
"...": "message specific fields"
|
||||
}
|
||||
```
|
||||
|
||||
When using the unified socket, the client can also include:
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "live|chat",
|
||||
"t": "message_type"
|
||||
}
|
||||
```
|
||||
|
||||
### Server to client
|
||||
|
||||
Legacy `live` mode uses:
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "message_type",
|
||||
"data": {}
|
||||
}
|
||||
```
|
||||
|
||||
Unified `chat` mode uses:
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"type": "message_type",
|
||||
"data": {}
|
||||
}
|
||||
```
|
||||
|
||||
Some forwarded `chat` frames may also contain `t`, `streaming`, `chain_type`, `message_id`, or `session_id`.
|
||||
|
||||
## Live Mode
|
||||
|
||||
### Client messages
|
||||
|
||||
#### `start_speaking`
|
||||
|
||||
Start a voice capture segment.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "start_speaking",
|
||||
"stamp": "seg_001"
|
||||
}
|
||||
```
|
||||
|
||||
#### `speaking_part`
|
||||
|
||||
Send one audio frame.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "speaking_part",
|
||||
"data": "<base64_pcm_bytes>"
|
||||
}
|
||||
```
|
||||
|
||||
#### `end_speaking`
|
||||
|
||||
Finish the current voice capture segment.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "end_speaking",
|
||||
"stamp": "seg_001"
|
||||
}
|
||||
```
|
||||
|
||||
#### `text_input`
|
||||
|
||||
Send a plain text input directly while using `ct=live`. The server will still route through Live mode with TTS and interrupt handling.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "text_input",
|
||||
"text": "Hello, what is the weather today?"
|
||||
}
|
||||
```
|
||||
|
||||
#### `interrupt`
|
||||
|
||||
Interrupt the current model or TTS response.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "interrupt"
|
||||
}
|
||||
```
|
||||
|
||||
### Server messages
|
||||
|
||||
#### `metrics`
|
||||
|
||||
Performance and provider metadata.
|
||||
|
||||
Example:
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "metrics",
|
||||
"data": {
|
||||
"wav_assemble_time": 0.12,
|
||||
"stt": "whisper_api",
|
||||
"llm_ttft": 0.84,
|
||||
"tts_total_time": 1.72
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### `user_msg`
|
||||
|
||||
STT result from the uploaded audio.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "user_msg",
|
||||
"data": {
|
||||
"text": "Hello there",
|
||||
"ts": 1710000000000
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### `bot_delta_chunk`
|
||||
|
||||
Raw model text delta. This is the token or chunk level stream and is not sentence segmented.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "bot_delta_chunk",
|
||||
"data": {
|
||||
"text": "Hel"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Notes:
|
||||
|
||||
- This event is generated directly from the model streaming path.
|
||||
- It is independent from TTS chunking.
|
||||
- Consumers should append `data.text` to a local buffer.
|
||||
|
||||
#### `bot_text_chunk`
|
||||
|
||||
Text associated with the current TTS chunk. This is usually sentence or phrase segmented.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "bot_text_chunk",
|
||||
"data": {
|
||||
"text": "Hello there."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Notes:
|
||||
|
||||
- This event is aligned to TTS output, not raw token streaming.
|
||||
- It may be coarser than `bot_delta_chunk`.
|
||||
|
||||
#### `response`
|
||||
|
||||
One TTS audio chunk, Base64 encoded.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "response",
|
||||
"data": "<base64_audio_bytes>"
|
||||
}
|
||||
```
|
||||
|
||||
#### `bot_msg`
|
||||
|
||||
Final bot text when the response completed without audio streaming.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "bot_msg",
|
||||
"data": {
|
||||
"text": "Final reply text",
|
||||
"ts": 1710000001234
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### `stop_play`
|
||||
|
||||
Stop client-side audio playback because the response was interrupted.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "stop_play"
|
||||
}
|
||||
```
|
||||
|
||||
#### `end`
|
||||
|
||||
Marks the end of the current response turn.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "end"
|
||||
}
|
||||
```
|
||||
|
||||
#### `error`
|
||||
|
||||
Recoverable or terminal processing error.
|
||||
|
||||
```json
|
||||
{
|
||||
"t": "error",
|
||||
"data": "error message"
|
||||
}
|
||||
```
|
||||
|
||||
## Unified Chat Mode
|
||||
|
||||
Set `ct=chat` on the Open API endpoint or include `"ct": "chat"` in each client frame when using `/api/unified_chat/ws`.
|
||||
|
||||
### Client messages
|
||||
|
||||
#### `bind`
|
||||
|
||||
Subscribe to an existing webchat session.
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"t": "bind",
|
||||
"session_id": "session_001"
|
||||
}
|
||||
```
|
||||
|
||||
#### `send`
|
||||
|
||||
Send a chat request.
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"t": "send",
|
||||
"username": "alice",
|
||||
"session_id": "session_001",
|
||||
"message_id": "msg_001",
|
||||
"message": [
|
||||
{
|
||||
"type": "plain",
|
||||
"text": "Please summarize this"
|
||||
}
|
||||
],
|
||||
"selected_provider": "openai_chat_completion",
|
||||
"selected_model": "gpt-4.1-mini",
|
||||
"enable_streaming": true
|
||||
}
|
||||
```
|
||||
|
||||
`message` uses the same message-part schema as `POST /api/v1/chat`.
|
||||
|
||||
#### `interrupt`
|
||||
|
||||
Interrupt the current chat response.
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"t": "interrupt"
|
||||
}
|
||||
```
|
||||
|
||||
### Server messages
|
||||
|
||||
#### `session_bound`
|
||||
|
||||
Acknowledges a successful `bind`.
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"type": "session_bound",
|
||||
"session_id": "session_001",
|
||||
"message_id": "ws_sub_xxx"
|
||||
}
|
||||
```
|
||||
|
||||
#### Forwarded streaming events
|
||||
|
||||
The server forwards the normal webchat queue payloads. Common examples:
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"type": "plain",
|
||||
"data": "Hello",
|
||||
"streaming": true,
|
||||
"chain_type": null,
|
||||
"message_id": "msg_001"
|
||||
}
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"type": "image",
|
||||
"data": "[IMAGE]file.jpg",
|
||||
"streaming": false,
|
||||
"message_id": "msg_001"
|
||||
}
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"type": "agent_stats",
|
||||
"data": {
|
||||
"time_to_first_token": 0.8
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"type": "message_saved",
|
||||
"data": {
|
||||
"id": 123,
|
||||
"created_at": "2026-03-16T10:00:00Z"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"type": "end",
|
||||
"data": "",
|
||||
"streaming": false,
|
||||
"message_id": "msg_001"
|
||||
}
|
||||
```
|
||||
|
||||
#### Chat errors
|
||||
|
||||
```json
|
||||
{
|
||||
"ct": "chat",
|
||||
"t": "error",
|
||||
"code": "INVALID_MESSAGE_FORMAT",
|
||||
"data": "message must be list"
|
||||
}
|
||||
```
|
||||
|
||||
## Recommended Client Strategy
|
||||
|
||||
For `live` mode:
|
||||
|
||||
1. Append every `bot_delta_chunk.data.text` into a raw transcript buffer.
|
||||
2. Use `bot_text_chunk` only when you need text aligned with audio playback.
|
||||
3. Decode and play each `response` audio chunk in arrival order.
|
||||
4. Reset per-turn buffers after `end`.
|
||||
|
||||
For `chat` mode:
|
||||
|
||||
1. Treat `plain + streaming=true` as incremental text.
|
||||
2. Treat `complete` or `end` as the end of a response turn.
|
||||
3. Persist `message_saved` metadata if you need server-side history IDs.
|
||||
|
||||
## Compatibility Notes
|
||||
|
||||
- `bot_text_chunk` remains sentence or phrase segmented for TTS compatibility.
|
||||
- `bot_delta_chunk` is the new delta-level text event for real-time rendering.
|
||||
- The legacy JWT endpoints and the new Open API endpoint share the same runtime behavior after authentication.
|
||||
@@ -257,6 +257,56 @@
|
||||
}
|
||||
}
|
||||
},
|
||||
"/api/v1/live/ws": {
|
||||
"get": {
|
||||
"tags": [
|
||||
"Open API"
|
||||
],
|
||||
"summary": "Live API WebSocket",
|
||||
"description": "WebSocket endpoint for Live API. Authenticate with API Key using query parameter `api_key` or header `Authorization: Bearer <api_key>`, and pass `username` as a query parameter. Use `ct=live` for voice mode or `ct=chat` for unified chat mode. See docs/live-api/README.md for the full frame-level protocol.",
|
||||
"security": [
|
||||
{
|
||||
"ApiKeyHeader": []
|
||||
}
|
||||
],
|
||||
"parameters": [
|
||||
{
|
||||
"name": "username",
|
||||
"in": "query",
|
||||
"required": true,
|
||||
"schema": {
|
||||
"type": "string"
|
||||
},
|
||||
"description": "Target username for the live session."
|
||||
},
|
||||
{
|
||||
"name": "ct",
|
||||
"in": "query",
|
||||
"schema": {
|
||||
"type": "string",
|
||||
"enum": [
|
||||
"live",
|
||||
"chat"
|
||||
],
|
||||
"default": "live"
|
||||
},
|
||||
"description": "Session mode. `live` for voice conversation, `ct=chat` for the unified chat WebSocket."
|
||||
}
|
||||
],
|
||||
"responses": {
|
||||
"101": {
|
||||
"description": "WebSocket protocol switch"
|
||||
},
|
||||
"401": {
|
||||
"$ref": "#/components/responses/Unauthorized"
|
||||
},
|
||||
"403": {
|
||||
"$ref": "#/components/responses/Forbidden"
|
||||
}
|
||||
},
|
||||
"x-websocket": true
|
||||
}
|
||||
},
|
||||
"/api/v1/im/message": {
|
||||
"post": {
|
||||
"tags": [
|
||||
|
||||
@@ -41,4 +41,4 @@ AstrBot 已经上架至雨云的预装软件列表,支持**一键安装** Astr
|
||||
|
||||
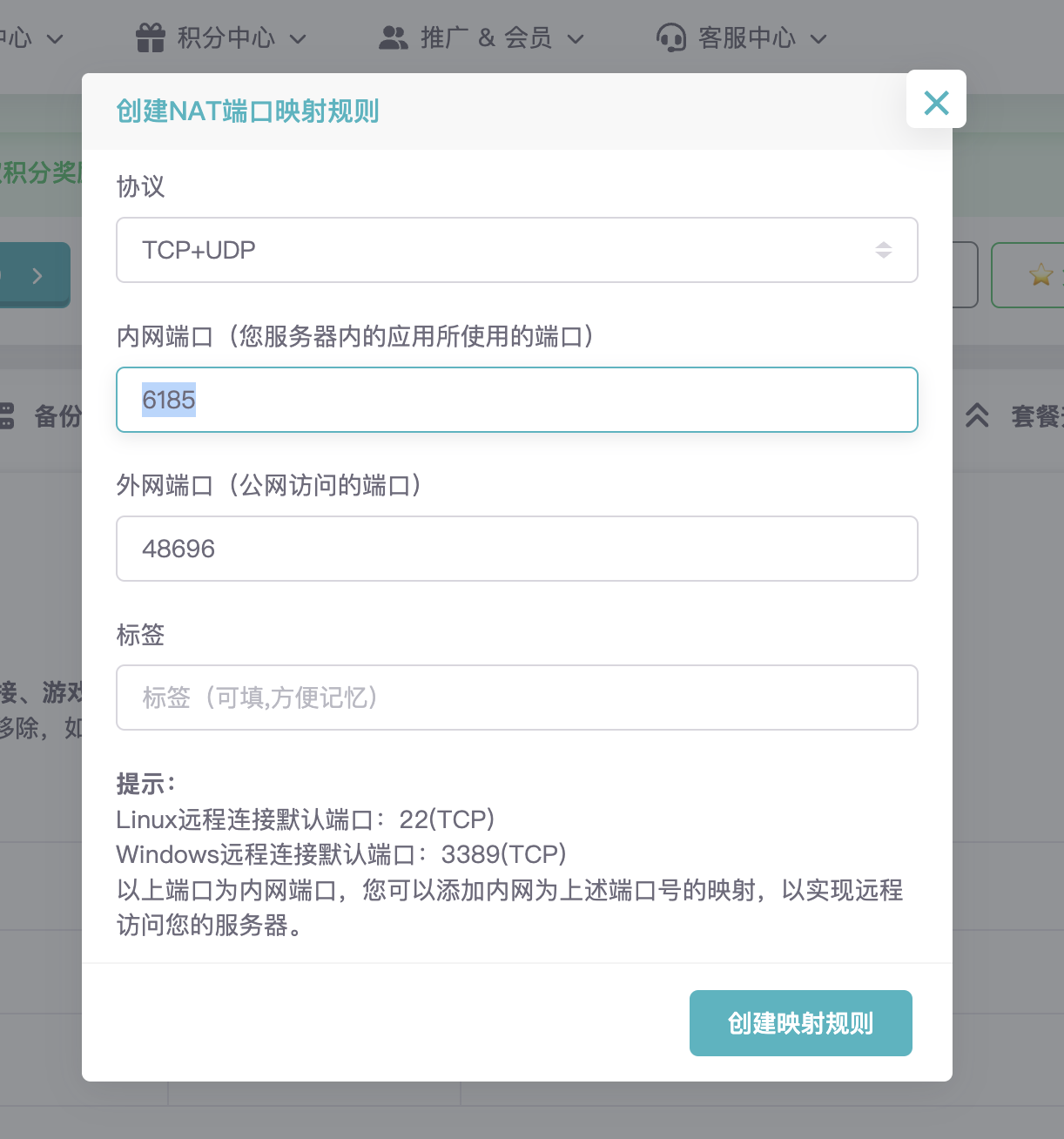
|
||||
|
||||
然后,内网端口填写 `6185`,点击 `创建映射规则`,这样就可以通过 `http://IP:上面设置好的外网端口` 访问 AstrBot 的管理面板了。
|
||||
然后,内网端口填写 `6185`,点击 `创建映射规则`,这样就可以通过 `http://IP:上面设置好的外网端口` 访问 AstrBot 的管理面板了。如果无法打开,请点击`备用地址`,通过备用地址访问管理面板。
|
||||
|
||||
@@ -46,6 +46,7 @@ X-API-Key: abk_xxx
|
||||
调用 AstrBot 内建的 Agent 进行对话交互。支持插件调用、工具调用等能力,与 IM 端对话能力一致。
|
||||
|
||||
- `POST /api/v1/chat`:发送对话消息(SSE 流式返回,不传 `session_id` 会自动创建 UUID)
|
||||
- `GET /api/v1/live/ws`:Live API WebSocket(API Key 鉴权,查询参数必须包含 `username`,可选 `ct=live|chat`)
|
||||
- `GET /api/v1/chat/sessions`:分页获取指定 `username` 的会话
|
||||
- `GET /api/v1/configs`:获取可用配置文件列表
|
||||
|
||||
@@ -148,3 +149,7 @@ curl -N 'http://localhost:6185/api/v1/chat' \
|
||||
交互式 API 文档请查看:
|
||||
|
||||
- https://docs.astrbot.app/scalar.html
|
||||
|
||||
Live API 协议说明请查看:
|
||||
|
||||
- `docs/live-api/README.md`
|
||||
|
||||
@@ -1,43 +0,0 @@
|
||||
# 接入 OneBot v11 协议实现
|
||||
|
||||
OneBot 是一个聊天机器人应用接口标准,旨在统一不同聊天平台上的机器人应用开发接口,使开发者只需编写一次业务逻辑代码即可应用到多种机器人平台。
|
||||
|
||||
AstrBot 支持接入所有适配了 OneBotv11 反向 Websockets(AstrBot 做服务器端)的机器人协议端。
|
||||
|
||||
下文给出一些常见的 OneBot v11 协议实现端项目。
|
||||
|
||||
- [NapCat](https://github.com/NapNeko/NapCatQQ)
|
||||
- [OneDisc](https://github.com/ITCraftDevelopmentTeam/OneDisc)
|
||||
- [Tele-KiraLink](https://github.com/Echomirix/Tele-KiraLink)
|
||||
|
||||
请参阅对应的协议实现端项目的部署文档。
|
||||
|
||||
## 1. 配置 OneBot v11
|
||||
|
||||
1. 进入 AstrBot 的 WebUI
|
||||
2. 点击左边栏 `机器人`
|
||||
3. 然后在右边的界面中,点击 `+ 创建机器人`
|
||||
4. 选择 `OneBot v11`
|
||||
|
||||
在出现的表单中,填写:
|
||||
|
||||
- ID(id):随意填写,仅用于区分不同的消息平台实例。
|
||||
- 启用(enable): 勾选。
|
||||
- 反向 WebSocket 主机地址:请填写你的机器的 IP 地址,一般情况下请直接填写 `0.0.0.0`
|
||||
- 反向 WebSocket 端口:填写一个端口,默认为 `6199`。
|
||||
- 反向 Websocket Token:只有当 NapCat 网络配置中配置了 token 才需填写。
|
||||
|
||||
点击 `保存`。
|
||||
|
||||
## 2. 配置协议实现端
|
||||
|
||||
请参阅对应的协议实现端项目的部署文档。
|
||||
|
||||
一些注意点:
|
||||
|
||||
1. 协议实现端需要支持 `反向 WebSocket` 实现,及 AstrBot 端作为服务端,实现端作为客户端。
|
||||
2. `反向 WebSocket` 的 URL 为 `ws(s)://<your-host>:6199/ws`。
|
||||
|
||||
## 3. 验证
|
||||
|
||||
前往 AstrBot WebUI `控制台`,如果出现 ` aiocqhttp(OneBot v11) 适配器已连接。` 蓝色的日志,说明连接成功。如果没有,若干秒后出现` aiocqhttp 适配器已被关闭` 则为连接超时(失败),请检查配置是否正确。
|
||||
@@ -0,0 +1,61 @@
|
||||
# 接入 Lagrange
|
||||
|
||||
> [!TIP]
|
||||
>
|
||||
> - 请合理控制使用频率。过于频繁地发送消息可能会被判定为异常行为,增加触发风控机制的风险。
|
||||
> - 本项目严禁用于任何违反法律法规的用途。若您意图将 AstrBot 应用于非法产业或活动,我们**明确反对并拒绝**您使用本项目。
|
||||
> - 最新的部署方式请以 [Lagrange Doc](https://lagrangedev.github.io/Lagrange.Doc/Lagrange.OneBot/Config/#%E4%B8%8B%E8%BD%BD%E5%AE%89%E8%A3%85) 为准。
|
||||
|
||||
## 下载
|
||||
|
||||
从 [GitHub Release](https://github.com/LagrangeDev/Lagrange.Core/releases) 下载最新版的 `Lagrange.OneBot`。
|
||||
|
||||
对于 Windows 设备,请下载 `Lagrange.OneBot_win-x64_xxxx` 压缩包。
|
||||
|
||||
对于 X86 的 Linux 用户,下载 `Lagrange.OneBot_linux-x64_xxx` 压缩包。
|
||||
|
||||
对于 Arm 的 Linux 用户,下载 `Lagrange.OneBot_linux-arm64_xxx` 压缩包。
|
||||
|
||||
对于 M 芯片 Mac 用户,下载 `Lagrange.OneBot_osx-arm64_xxx` 压缩包。
|
||||
|
||||
对于 Intel 芯片 Mac 用户,下载 `Lagrange.OneBot_osx-x64_xxx` 压缩包。
|
||||
|
||||
## 部署
|
||||
|
||||
请参阅 [Lagrange Doc](https://lagrangedev.github.io/Lagrange.Doc/Lagrange.OneBot/Config/#%E8%BF%90%E8%A1%8C)。
|
||||
|
||||
运行完成后,请修改 [配置文件](https://lagrangedev.github.io/Lagrange.Doc/Lagrange.OneBot/Config/#%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6),
|
||||
|
||||
在 `Implementations` 字段下添加:
|
||||
|
||||
```json
|
||||
{
|
||||
"Type": "ReverseWebSocket",
|
||||
"Host": "127.0.0.1",
|
||||
"Port": 6199,
|
||||
"Suffix": "/ws",
|
||||
"ReconnectInterval": 5000,
|
||||
"HeartBeatInterval": 5000,
|
||||
"AccessToken": ""
|
||||
}
|
||||
```
|
||||
|
||||
一定要保证 `Suffix` 为 `/ws`。
|
||||
|
||||
## 连接到 AstrBot
|
||||
|
||||
### 配置 aiocqhttp
|
||||
|
||||
1. 进入 AstrBot 的管理面板
|
||||
2. 点击左边栏 `机器人`
|
||||
3. 然后在右边的界面中,点击 `+ 创建机器人`
|
||||
4. 选择 `aiocqhttp(OneBotv11)`
|
||||
|
||||
弹出的配置项填写:
|
||||
|
||||
配置项填写:
|
||||
|
||||
- ID(id):随意填写,用于区分不同的消息平台实例。
|
||||
- 启用(enable): 勾选。
|
||||
- 反向 WebSocket 主机地址:请填写你的机器的 IP 地址。一般情况下请直接填写 `0.0.0.0`
|
||||
- 反向 WebSocket 端口:填写一个端口,例如 `6199`。
|
||||
@@ -0,0 +1,134 @@
|
||||
# 使用 NapCat
|
||||
|
||||
> [!TIP]
|
||||
>
|
||||
> - 本项目严禁用于任何违反法律法规的用途。若您意图将 AstrBot 应用于非法产业或活动,我们**明确反对并拒绝**您使用本项目。
|
||||
> - AstrBot 通过 `aiocqhttp` 适配器接入 OneBot v11 协议。OneBot v11 协议是一个开放的通信协议,并不代表任何具体的软件或服务。
|
||||
|
||||
NapCat 的 GitHub 仓库:[NapCat](https://github.com/NapNeko/NapCatQQ)
|
||||
NapCat 的文档:[NapCat 文档](https://napcat.napneko.icu/)
|
||||
|
||||
NapCat 提供了大量的部署方式,包括 Docker、Windows 一键安装包等等。
|
||||
|
||||
## 通过一键脚本部署
|
||||
|
||||
推荐采用这种方式部署。
|
||||
|
||||
### Windows
|
||||
|
||||
看这篇文章:[NapCat.Shell - Win手动启动教程](https://napneko.github.io/guide/boot/Shell#napcat-shell-win%E6%89%8B%E5%8A%A8%E5%90%AF%E5%8A%A8%E6%95%99%E7%A8%8B)
|
||||
|
||||
### Linux
|
||||
|
||||
看这篇文章:[NapCat.Installer - Linux一键使用脚本(支持Ubuntu 20+/Debian 10+/Centos9)](https://napneko.github.io/guide/boot/Shell#napcat-installer-linux%E4%B8%80%E9%94%AE%E4%BD%BF%E7%94%A8%E8%84%9A%E6%9C%AC-%E6%94%AF%E6%8C%81ubuntu-20-debian-10-centos9)
|
||||
|
||||
> [!TIP]
|
||||
> **Napcat WebUI 在哪打开**:
|
||||
> 在 napcat 的日志里会显示 WebUI 链接。
|
||||
>
|
||||
> 如果是 linux 命令行一键部署的napcat:`docker log <账号>`。
|
||||
>
|
||||
> Docker部署的 NapCat:`docker logs napcat`。
|
||||
|
||||
## 通过 Docker Compose 部署
|
||||
|
||||
1. 下载或复制 [astrbot.yml](https://github.com/NapNeko/NapCat-Docker/blob/main/compose/astrbot.yml) 内容
|
||||
2. 将刚刚下载的文件重命名为 `astrbot.yml`
|
||||
3. 编辑 `astrbot.yml`,将 `# - "6199:6199"` 修改为 `- "6199:6199"`,移除开头的 `#`
|
||||
4. 在 `astrbot.yml` 文件所在目录执行:
|
||||
|
||||
```bash
|
||||
NAPCAT_UID=$(id -u) NAPCAT_GID=$(id -g) docker compose -f ./astrbot.yml up -d
|
||||
```
|
||||
|
||||
## 通过 Docker 部署
|
||||
|
||||
此教程默认您安装了 Docker。
|
||||
|
||||
在终端执行以下命令即可一键部署。
|
||||
|
||||
```bash
|
||||
docker run -d \
|
||||
-e NAPCAT_GID=$(id -g) \
|
||||
-e NAPCAT_UID=$(id -u) \
|
||||
-p 3000:3000 \
|
||||
-p 3001:3001 \
|
||||
-p 6099:6099 \
|
||||
--name napcat \
|
||||
--restart=always \
|
||||
mlikiowa/napcat-docker:latest
|
||||
```
|
||||
|
||||
执行成功后,需要查看日志以得到登录二维码和管理面板的 URL。
|
||||
|
||||
```bash
|
||||
docker logs napcat
|
||||
```
|
||||
|
||||
请复制管理面板的 URL,然后在浏览器中打开备用。
|
||||
|
||||
然后使用你要登录的账号扫描出现的二维码,即可登录。
|
||||
|
||||
如果登录阶段没有出现问题,即成功部署。
|
||||
|
||||
## 连接到 AstrBot
|
||||
|
||||
## 在 AstrBot 配置 aiocqhttp
|
||||
|
||||
1. 进入 AstrBot 的管理面板
|
||||
2. 点击左边栏 `机器人`
|
||||
3. 然后在右边的界面中,点击 `+ 创建机器人`
|
||||
4. 选择 `OneBot v11`
|
||||
|
||||
弹出的配置项填写:
|
||||
- ID(id):随意填写,仅用于区分不同的消息平台实例。
|
||||
- 启用(enable): 勾选。
|
||||
- 反向 WebSocket 主机地址:请填写你的机器的 IP 地址,一般情况下请直接填写 `0.0.0.0`
|
||||
- 反向 WebSocket 端口:填写一个端口,默认为 `6199`。
|
||||
- 反向 Websocket Token:只有当 NapCat 网络配置中配置了 token 才需填写。
|
||||
|
||||
图例:(最快只需要点击启用,然后保存即可)
|
||||
|
||||
<img width="818" height="799" alt="xinjianya" src="https://github.com/user-attachments/assets/813ac338-2fd7-4add-bde4-8b0f6d0bda95" />
|
||||
|
||||
|
||||
点击 `保存`。
|
||||
|
||||
### 配置管理员
|
||||
|
||||
填写完毕后,进入 `配置文件` 页,点击 `平台配置` 选项卡,找到 `管理员 ID`,填写你的账号(不是机器人的账号)。
|
||||
|
||||
切记点击右下角 `保存`,AstrBot 重启并会应用配置。
|
||||
|
||||
### 在 NapCat 中添加 WebSocket 客户端
|
||||
|
||||
切换回 NapCat 的管理面板,点击 `网络配置->新建->WebSockets客户端`。
|
||||
|
||||
<img width="649" height="751" alt="jiaochenXJY" src="https://github.com/user-attachments/assets/5044f96a-a81f-407a-a3b1-0c518499eda4" />
|
||||
|
||||
|
||||
在新弹出的窗口中:
|
||||
|
||||
- 勾选 `启用`。
|
||||
- `URL` 填写 `ws://宿主机IP:端口/ws`。如 `ws://localhost:6199/ws` 或 `ws://127.0.0.1:6199/ws`。
|
||||
|
||||
> [!IMPORTANT]
|
||||
> 1. 如果采用 Docker 部署并同时把 AstrBot 和 NapCat 两个容器接入了同一网络,`ws://astrbot:6199/ws`(参考本文档的 Docker 脚本)。
|
||||
> 2. 由于 Docker 网络隔离的原因,不在同一个网络时请使用内网 IP 地址或公网 IP 地址 ***(不安全)*** 进行连接,即 `ws://(内网/公网):6199/ws`。
|
||||
|
||||
- 消息格式:`Array`
|
||||
- 心跳间隔: `5000`
|
||||
- 重连间隔: `5000`
|
||||
|
||||
> [!WARNING]
|
||||
>
|
||||
> 1. 切记后面加一个 `/ws`!
|
||||
> 2. 这里的 IP 不能填为 `0.0.0.0`
|
||||
|
||||
点击 `保存`。
|
||||
|
||||
前往 AstrBot WebUI `控制台`,如果出现 ` aiocqhttp(OneBot v11) 适配器已连接。` 蓝色的日志,说明连接成功。如果没有,若干秒后出现` aiocqhttp 适配器已被关闭` 则为连接超时(失败),请检查配置是否正确。
|
||||
|
||||
## 🎉 大功告成
|
||||
|
||||
此时,你的 AstrBot 和 NapCat 应该已经连接成功!使用 `私聊` 的方式对机器人发送 `/help` 以检查是否连接成功。
|
||||
@@ -0,0 +1 @@
|
||||
支持接入所有适配了 OneBotv11 反向 Websockets(AstrBot 做服务器端) 的机器人协议端。
|
||||
@@ -1,32 +0,0 @@
|
||||
# 接入 Satori 协议
|
||||
|
||||
## Satori 协议简介
|
||||
|
||||
> 摘录自:https://satori.chat/zh-CN/introduction.html
|
||||
|
||||
Satori 是一个通用的聊天协议。Satori 协议希望能够抹平不同聊天平台之间的差异,让开发者以更低的成本开发出跨平台、可扩展、高性能的聊天应用。
|
||||
|
||||
Satori 的名称来源于游戏东方 Project 中的角色 [古明地觉 (Komeiji Satori)](https://zh.touhouwiki.net/wiki/%E5%8F%A4%E6%98%8E%E5%9C%B0%E8%A7%89)。古明地觉能够以心灵感应的方式与各种动物交流,取这个名字是希望 Satori 能够成为各个聊天平台之间的桥梁。
|
||||
|
||||
Satori 的开发团队长期从事聊天机器人开发,熟悉各种聊天平台的通信方式。经过长达 4 年的发展,Satori 有了健全的设计和完善的实现。目前,Satori 官方提供了超过 15 个聊天平台的适配器,完全覆盖了世界上主流的聊天平台,如 QQ、Discord、企业微信、KOOK 等等。
|
||||
|
||||
## 1. 配置协议实现端
|
||||
|
||||
请参阅对应的协议实现端项目的部署文档。
|
||||
|
||||
## 2. 配置 Satori 协议
|
||||
|
||||
1. 进入 AstrBot 的 WebUI
|
||||
2. 点击左边栏 `机器人`
|
||||
3. 然后在右边的界面中,点击 `+ 创建机器人`
|
||||
4. 选择 `Satori`
|
||||
|
||||
弹出的配置项填写:
|
||||
|
||||
- 机器人名称 (id): `satori` (随意)
|
||||
- 启用 (enable): 勾选
|
||||
- Satori API 终结点 (satori_api_base_url):`http://localhost:5600/v1`(端口和上面配置的协议端端口一致)
|
||||
- Satori WebSocket 终结点 (satori_endpoint):`ws://localhost:5600/v1/events`(端口和上面配置的协议端端口一致)
|
||||
- Satori 令牌 (satori_token):根据协议端配置情况选择填写
|
||||
|
||||
点击 `保存`。
|
||||
@@ -0,0 +1,78 @@
|
||||
# 接入 LLTwoBot (Satori)
|
||||
|
||||
> [!TIP]
|
||||
> LLTwoBot 是一个基于 QQNT 的 Onebot v11、Satori 多协议实现端,可以让你在 QQ 平台使用 Satori 协议与 AstrBot 进行通信。
|
||||
|
||||
> [!TIP]
|
||||
>
|
||||
> - 请合理控制使用频率。过于频繁地发送消息可能会被判定为异常行为,增加触发风控机制的风险。
|
||||
> - 本项目严禁用于任何违反法律法规的用途。若您意图将 AstrBot 应用于非法产业或活动,我们**明确反对并拒绝**您使用本项目。
|
||||
|
||||
## 准备工作
|
||||
|
||||
请先参考 LLTwoBot 官方文档完成基础配置:
|
||||
[LLTwoBot 文档](https://llonebot.com/guide/getting-started)
|
||||
|
||||
完成文档中的步骤,确保你已经:
|
||||
|
||||
1. 下载并安装了 LLTwoBot
|
||||
2. 成功登录了 QQ 账号
|
||||
|
||||
## 配置 LLTwoBot 的 Satori 服务
|
||||
|
||||
在成功登录 QQ 后,先打开 LLTwoBot 的 WebUI 配置界面。
|
||||
> WebUI 默认地址为:<http://localhost:3080/>
|
||||
|
||||
---
|
||||
|
||||
在WebUI的配置界面侧边,选择【Satori】选项卡,进行如下配置:
|
||||
|
||||
1. 确认【启用 Satori 协议】配置项已开启
|
||||
2. 端口默认为 5600(如需修改请记住新端口)
|
||||
3. 如有必要,可填写【Satori Token】
|
||||
4. 点击右下角的【保存配置】
|
||||
|
||||
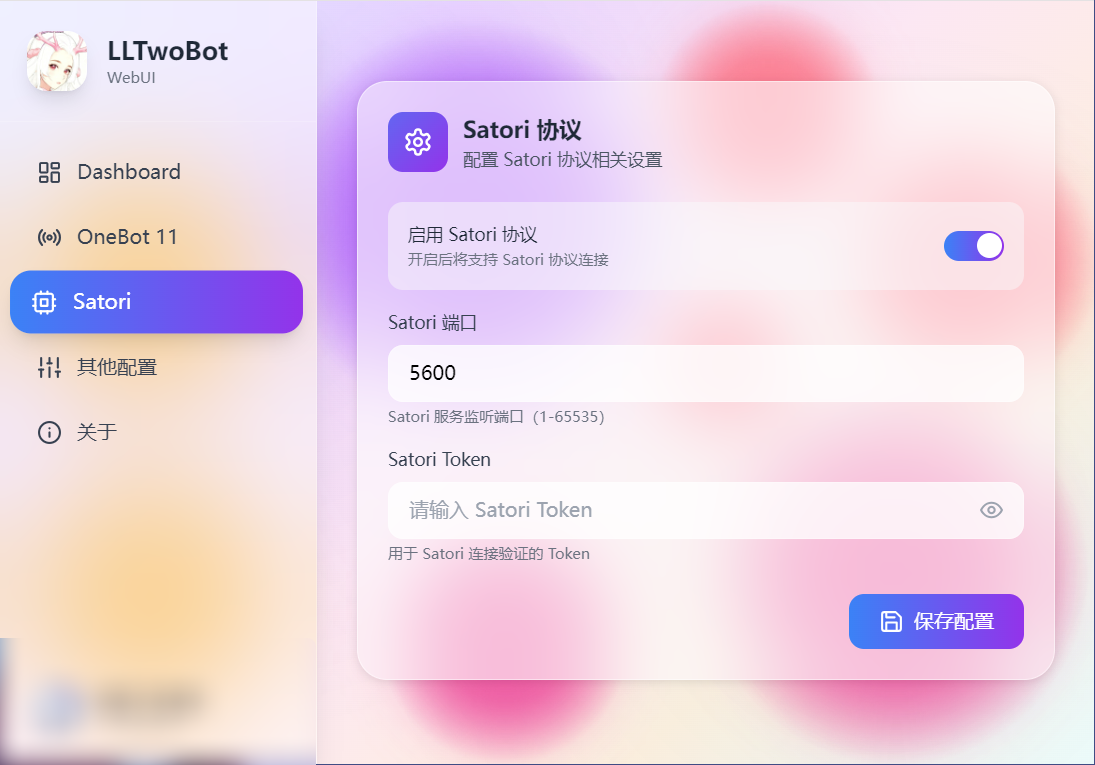
|
||||
|
||||
## 在 AstrBot 中配置 Satori 适配器
|
||||
|
||||
1. 进入 AstrBot 的管理面板
|
||||
2. 点击左边栏 `机器人`
|
||||
3. 然后在右边的界面中,点击 `+ 创建机器人`
|
||||
4. 选择 `satori`
|
||||
|
||||
弹出的配置项填写:
|
||||
|
||||
- 机器人名称 (id): `LLTwoBot`
|
||||
- 启用 (enable): 勾选
|
||||
- Satori API 终结点 (satori_api_base_url):`http://localhost:5600/v1`
|
||||
- Satori WebSocket 终结点 (satori_endpoint):`ws://localhost:5600/v1/events`
|
||||
- Satori 令牌 (satori_token):根据 LLTwoBot 配置填写(如有设置)
|
||||
|
||||
> [!NOTE]
|
||||
>
|
||||
> - LLTwoBot 的 satori协议 默认在 `5600` 端口提供服务
|
||||
> - 因此完整的 URL 路径为 `http://localhost:5600/v1`
|
||||
>
|
||||
> 如果你的 satori协议运行在其他端口,请根据实际情况修改对应的配置!
|
||||
|
||||
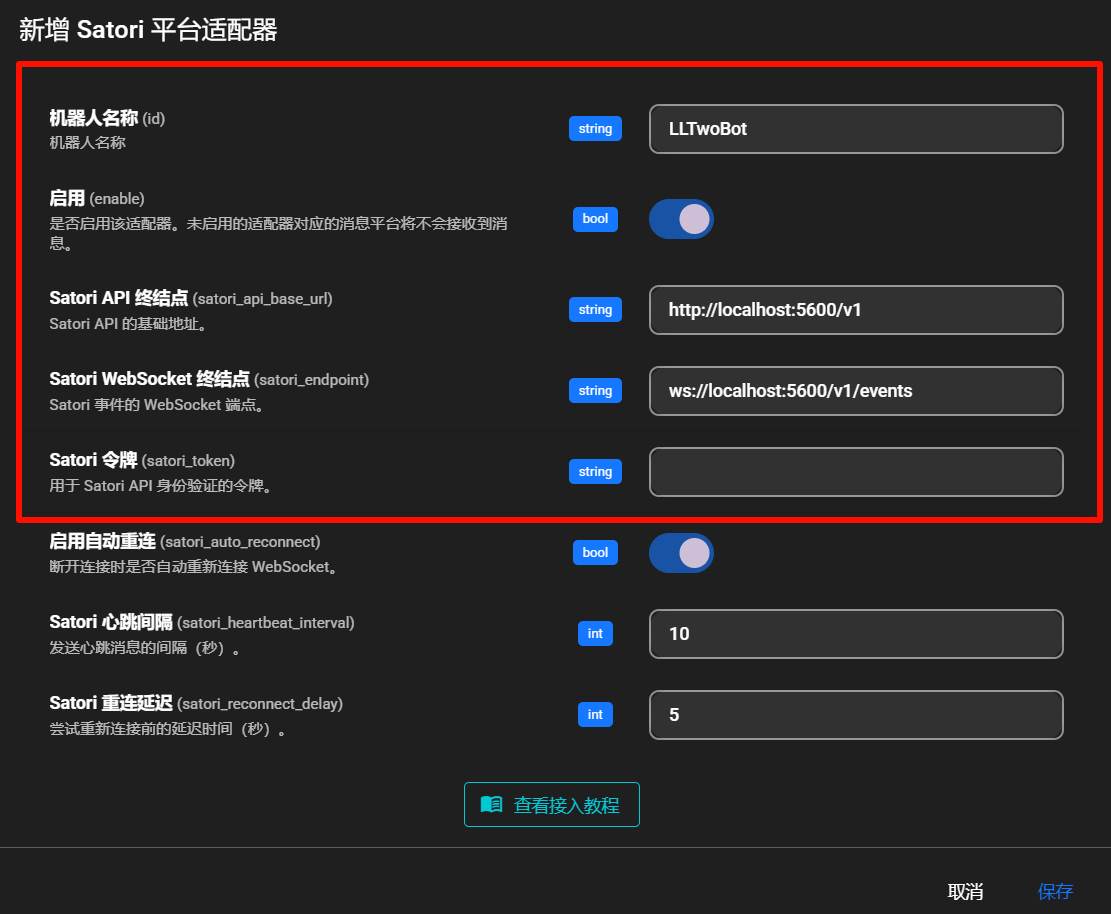
|
||||
|
||||
点击右下角 `保存` 完成配置。
|
||||
|
||||
## 🎉 大功告成
|
||||
|
||||
此时,你的 AstrBot 应该已经通过 Satori 协议成功连接到 LLTwoBot。
|
||||
|
||||
在 QQ 中发送 `/help` 以检查是否连接成功。
|
||||
|
||||
如果成功回复,则配置成功。
|
||||
|
||||
## 常见问题
|
||||
|
||||
如果遇到连接问题,请检查:
|
||||
|
||||
1. LLTwoBot 是否正常运行
|
||||
2. Satori 服务是否已启用
|
||||
3. 端口配置是否正确
|
||||
4. Token 是否匹配(如设置了 Token)
|
||||
@@ -257,6 +257,56 @@
|
||||
}
|
||||
}
|
||||
},
|
||||
"/api/v1/live/ws": {
|
||||
"get": {
|
||||
"tags": [
|
||||
"Open API"
|
||||
],
|
||||
"summary": "Live API WebSocket",
|
||||
"description": "WebSocket endpoint for Live API. Authenticate with API Key using query parameter `api_key` or header `Authorization: Bearer <api_key>`, and pass `username` as a query parameter. Use `ct=live` for voice mode or `ct=chat` for unified chat mode. See docs/live-api/README.md for the full frame-level protocol.",
|
||||
"security": [
|
||||
{
|
||||
"ApiKeyHeader": []
|
||||
}
|
||||
],
|
||||
"parameters": [
|
||||
{
|
||||
"name": "username",
|
||||
"in": "query",
|
||||
"required": true,
|
||||
"schema": {
|
||||
"type": "string"
|
||||
},
|
||||
"description": "Target username for the live session."
|
||||
},
|
||||
{
|
||||
"name": "ct",
|
||||
"in": "query",
|
||||
"schema": {
|
||||
"type": "string",
|
||||
"enum": [
|
||||
"live",
|
||||
"chat"
|
||||
],
|
||||
"default": "live"
|
||||
},
|
||||
"description": "Session mode. `live` for voice conversation, `chat` for the unified chat WebSocket."
|
||||
}
|
||||
],
|
||||
"responses": {
|
||||
"101": {
|
||||
"description": "WebSocket protocol switch"
|
||||
},
|
||||
"401": {
|
||||
"$ref": "#/components/responses/Unauthorized"
|
||||
},
|
||||
"403": {
|
||||
"$ref": "#/components/responses/Forbidden"
|
||||
}
|
||||
},
|
||||
"x-websocket": true
|
||||
}
|
||||
},
|
||||
"/api/v1/im/message": {
|
||||
"post": {
|
||||
"tags": [
|
||||
|
||||
@@ -1,5 +1,7 @@
|
||||
# user service
|
||||
[Unit]
|
||||
Description=AstrBot Service
|
||||
Documentation=https://github.com/AstrBotDevs/AstrBot
|
||||
After=network-online.target
|
||||
Wants=network-online.target
|
||||
|
||||
@@ -9,6 +11,9 @@ WorkingDirectory=%h/.local/share/astrbot
|
||||
ExecStart=/usr/bin/sh -c '/usr/bin/astrbot run || { /usr/bin/astrbot init && /usr/bin/astrbot run; }'
|
||||
Restart=on-failure
|
||||
RestartSec=5
|
||||
StandardOutput=journal
|
||||
StandardError=journal
|
||||
SyslogIdentifier=astrbot-%u
|
||||
Environment=PYTHONUNBUFFERED=1
|
||||
|
||||
[Install]
|
||||
|
||||
@@ -1,196 +0,0 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import subprocess
|
||||
import sys
|
||||
from collections import defaultdict
|
||||
from dataclasses import dataclass
|
||||
from datetime import datetime
|
||||
|
||||
|
||||
@dataclass(frozen=True)
|
||||
class Issue:
|
||||
number: int
|
||||
title: str
|
||||
created_at: datetime
|
||||
url: str
|
||||
|
||||
|
||||
def parse_args() -> argparse.Namespace:
|
||||
parser = argparse.ArgumentParser(
|
||||
description=(
|
||||
"Close duplicate open plugin-publish issues while keeping the latest one."
|
||||
)
|
||||
)
|
||||
parser.add_argument(
|
||||
"--repo",
|
||||
default="AstrBotDevs/AstrBot",
|
||||
help="GitHub repository in owner/name format.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--label",
|
||||
default="plugin-publish",
|
||||
help="Issue label to target.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--limit",
|
||||
type=int,
|
||||
default=1000,
|
||||
help="Maximum number of open issues to inspect.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--apply",
|
||||
action="store_true",
|
||||
help="Actually close duplicate issues. Defaults to dry-run.",
|
||||
)
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def run_gh_command(args: list[str]) -> str:
|
||||
try:
|
||||
completed = subprocess.run(
|
||||
args,
|
||||
check=True,
|
||||
capture_output=True,
|
||||
text=True,
|
||||
)
|
||||
except FileNotFoundError as exc:
|
||||
raise RuntimeError("GitHub CLI `gh` is not installed or not in PATH.") from exc
|
||||
except subprocess.CalledProcessError as exc:
|
||||
stderr = exc.stderr.strip()
|
||||
stdout = exc.stdout.strip()
|
||||
details = stderr or stdout or str(exc)
|
||||
raise RuntimeError(f"`{' '.join(args)}` failed: {details}") from exc
|
||||
return completed.stdout
|
||||
|
||||
|
||||
def load_open_issues(repo: str, label: str, limit: int) -> list[Issue]:
|
||||
output = run_gh_command(
|
||||
[
|
||||
"gh",
|
||||
"issue",
|
||||
"list",
|
||||
"--repo",
|
||||
repo,
|
||||
"--label",
|
||||
label,
|
||||
"--state",
|
||||
"open",
|
||||
"--limit",
|
||||
str(limit),
|
||||
"--json",
|
||||
"number,title,createdAt,url",
|
||||
]
|
||||
)
|
||||
items = json.loads(output)
|
||||
return [
|
||||
Issue(
|
||||
number=item["number"],
|
||||
title=item["title"],
|
||||
created_at=datetime.fromisoformat(item["createdAt"].replace("Z", "+00:00")),
|
||||
url=item["url"],
|
||||
)
|
||||
for item in items
|
||||
]
|
||||
|
||||
|
||||
def normalize_title(title: str) -> str:
|
||||
return " ".join(title.split()).strip()
|
||||
|
||||
|
||||
def find_duplicates(
|
||||
issues: list[Issue],
|
||||
) -> list[tuple[Issue, list[Issue]]]:
|
||||
grouped: dict[str, list[Issue]] = defaultdict(list)
|
||||
for issue in issues:
|
||||
grouped[normalize_title(issue.title)].append(issue)
|
||||
|
||||
duplicate_groups: list[tuple[Issue, list[Issue]]] = []
|
||||
for group in grouped.values():
|
||||
if len(group) < 2:
|
||||
continue
|
||||
ordered = sorted(
|
||||
group,
|
||||
key=lambda issue: (issue.created_at, issue.number),
|
||||
reverse=True,
|
||||
)
|
||||
keep = ordered[0]
|
||||
close_candidates = ordered[1:]
|
||||
duplicate_groups.append((keep, close_candidates))
|
||||
|
||||
duplicate_groups.sort(
|
||||
key=lambda item: (item[0].created_at, item[0].number),
|
||||
reverse=True,
|
||||
)
|
||||
return duplicate_groups
|
||||
|
||||
|
||||
def print_plan(duplicate_groups: list[tuple[Issue, list[Issue]]], apply: bool) -> None:
|
||||
action = "Will close" if apply else "Would close"
|
||||
if not duplicate_groups:
|
||||
print("No duplicate open issues found.")
|
||||
return
|
||||
|
||||
total_to_close = sum(len(close_list) for _, close_list in duplicate_groups)
|
||||
print(f"Found {len(duplicate_groups)} duplicate title groups.")
|
||||
print(
|
||||
f"{action} {total_to_close} issues and keep {len(duplicate_groups)} latest issues."
|
||||
)
|
||||
|
||||
for keep, close_list in duplicate_groups:
|
||||
print()
|
||||
print(f'Keep #{keep.number} [{keep.created_at.isoformat()}] "{keep.title}"')
|
||||
print(f" {keep.url}")
|
||||
for issue in close_list:
|
||||
print(
|
||||
f'Close #{issue.number} [{issue.created_at.isoformat()}] "{issue.title}"'
|
||||
)
|
||||
print(f" {issue.url}")
|
||||
|
||||
|
||||
def close_duplicates(
|
||||
repo: str, duplicate_groups: list[tuple[Issue, list[Issue]]]
|
||||
) -> None:
|
||||
for keep, close_list in duplicate_groups:
|
||||
reason = (
|
||||
f"Closing as duplicate of #{keep.number}. "
|
||||
"Keeping the latest open issue with this title."
|
||||
)
|
||||
for issue in close_list:
|
||||
print(f"Closing #{issue.number} as duplicate of #{keep.number}...")
|
||||
run_gh_command(
|
||||
[
|
||||
"gh",
|
||||
"issue",
|
||||
"close",
|
||||
str(issue.number),
|
||||
"--repo",
|
||||
repo,
|
||||
"--comment",
|
||||
reason,
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def main() -> int:
|
||||
args = parse_args()
|
||||
try:
|
||||
issues = load_open_issues(args.repo, args.label, args.limit)
|
||||
duplicate_groups = find_duplicates(issues)
|
||||
print_plan(duplicate_groups, apply=args.apply)
|
||||
if args.apply and duplicate_groups:
|
||||
print()
|
||||
close_duplicates(args.repo, duplicate_groups)
|
||||
print("Done.")
|
||||
elif not args.apply:
|
||||
print()
|
||||
print("Dry-run only. Re-run with `--apply` to close the duplicates.")
|
||||
except RuntimeError as exc:
|
||||
print(str(exc), file=sys.stderr)
|
||||
return 1
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
raise SystemExit(main())
|
||||
@@ -1,253 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
"""
|
||||
Auto-generate changelog from git commits using LLM.
|
||||
Usage: python scripts/generate_changelog.py [--version VERSION]
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import re
|
||||
import subprocess
|
||||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def get_latest_tag():
|
||||
"""Get the latest git tag."""
|
||||
result = subprocess.run(
|
||||
["git", "describe", "--tags", "--abbrev=0"],
|
||||
capture_output=True,
|
||||
text=True,
|
||||
check=True,
|
||||
)
|
||||
return result.stdout.strip()
|
||||
|
||||
|
||||
def get_commits_since_tag(tag):
|
||||
"""Get all commit messages since the specified tag."""
|
||||
result = subprocess.run(
|
||||
["git", "log", f"{tag}..HEAD", "--pretty=format:%H|%s|%b"],
|
||||
capture_output=True,
|
||||
text=True,
|
||||
check=True,
|
||||
)
|
||||
commits = []
|
||||
for line in result.stdout.strip().split("\n"):
|
||||
if not line:
|
||||
continue
|
||||
parts = line.split("|", 2)
|
||||
if len(parts) >= 2:
|
||||
commit_hash = parts[0]
|
||||
subject = parts[1]
|
||||
body = parts[2] if len(parts) > 2 else ""
|
||||
commits.append({"hash": commit_hash[:7], "subject": subject, "body": body})
|
||||
return commits
|
||||
|
||||
|
||||
def extract_issue_number(text):
|
||||
"""Extract issue number from commit message."""
|
||||
# Match #1234 or (#1234)
|
||||
match = re.search(r"#(\d+)", text)
|
||||
return match.group(1) if match else None
|
||||
|
||||
|
||||
def call_llm_for_changelog(commits, version):
|
||||
"""Call LLM to generate changelog from commits."""
|
||||
try:
|
||||
# Try to use OpenAI API or other LLM providers
|
||||
import openai
|
||||
|
||||
# Build prompt
|
||||
commits_text = "\n".join([f"- {c['subject']}" for c in commits])
|
||||
|
||||
prompt = f"""Based on the following git commit messages, generate a changelog document in BOTH Chinese and English.
|
||||
|
||||
Commit messages:
|
||||
{commits_text}
|
||||
|
||||
Please organize the changes into these categories:
|
||||
- 新增 (New Features)
|
||||
- 修复 (Bug Fixes)
|
||||
- 优化 (Improvements)
|
||||
- 其他 (Others)
|
||||
|
||||
Format requirements:
|
||||
1. Start with Chinese version under "## What's Changed"
|
||||
2. Follow with English version under "## What's Changed (EN)"
|
||||
3. Use markdown format with proper bullet points
|
||||
4. Keep descriptions concise and user-friendly
|
||||
5. If a commit mentions an issue number (#1234), include it in the format ([#1234](https://github.com/AstrBotDevs/AstrBot/issues/1234))
|
||||
|
||||
Example format:
|
||||
## What's Changed
|
||||
|
||||
### 新增
|
||||
- 支持某某功能 ([#1234](https://github.com/AstrBotDevs/AstrBot/issues/1234))
|
||||
|
||||
### 修复
|
||||
- 修复某某问题
|
||||
|
||||
## What's Changed (EN)
|
||||
|
||||
### New Features
|
||||
- Add support for something ([#1234](https://github.com/AstrBotDevs/AstrBot/issues/1234))
|
||||
|
||||
### Bug Fixes
|
||||
- Fix something
|
||||
"""
|
||||
|
||||
client = openai.OpenAI(
|
||||
api_key=os.getenv("OPENAI_API_KEY"),
|
||||
base_url=os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1"),
|
||||
)
|
||||
|
||||
response = client.chat.completions.create(
|
||||
model=os.getenv("OPENAI_MODEL", "gpt-4"),
|
||||
messages=[
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a helpful assistant that generates well-structured changelogs.",
|
||||
},
|
||||
{"role": "user", "content": prompt},
|
||||
],
|
||||
temperature=0.3,
|
||||
)
|
||||
|
||||
return response.choices[0].message.content
|
||||
|
||||
except ImportError:
|
||||
print(
|
||||
"Warning: openai package not installed. Install it with: pip install openai"
|
||||
)
|
||||
return generate_simple_changelog(commits)
|
||||
except Exception as e:
|
||||
print(f"Warning: Failed to call LLM API: {e}")
|
||||
print("Falling back to simple changelog generation...")
|
||||
return generate_simple_changelog(commits)
|
||||
|
||||
|
||||
def generate_simple_changelog(commits):
|
||||
"""Generate a simple changelog without LLM."""
|
||||
sections = {
|
||||
"feat": ("新增", "New Features", []),
|
||||
"fix": ("修复", "Bug Fixes", []),
|
||||
"perf": ("优化", "Improvements", []),
|
||||
"docs": ("文档", "Documentation", []),
|
||||
"refactor": ("重构", "Refactoring", []),
|
||||
"test": ("测试", "Tests", []),
|
||||
"chore": ("其他", "Chore", []),
|
||||
"other": ("其他", "Others", []),
|
||||
}
|
||||
|
||||
# Categorize commits by conventional commit type
|
||||
for commit in commits:
|
||||
subject = commit["subject"]
|
||||
issue_num = extract_issue_number(subject)
|
||||
issue_link = (
|
||||
f" ([#{issue_num}](https://github.com/AstrBotDevs/AstrBot/issues/{issue_num}))"
|
||||
if issue_num
|
||||
else ""
|
||||
)
|
||||
|
||||
# Detect conventional commit type
|
||||
matched = False
|
||||
for prefix in ["feat", "fix", "perf", "docs", "refactor", "test", "chore"]:
|
||||
if subject.lower().startswith(f"{prefix}:") or subject.lower().startswith(
|
||||
f"{prefix}("
|
||||
):
|
||||
# Remove prefix for display
|
||||
clean_subject = re.sub(
|
||||
r"^[a-z]+(\([^)]+\))?:\s*", "", subject, flags=re.IGNORECASE
|
||||
)
|
||||
sections[prefix][2].append(f"- {clean_subject}{issue_link}")
|
||||
matched = True
|
||||
break
|
||||
|
||||
if not matched:
|
||||
sections["other"][2].append(f"- {subject}{issue_link}")
|
||||
|
||||
# Build Chinese version
|
||||
changelog_zh = "## What's Changed\n\n"
|
||||
for section_key in ["feat", "fix", "perf", "docs", "refactor", "test", "other"]:
|
||||
zh_title, _, items = sections[section_key]
|
||||
if items:
|
||||
changelog_zh += f"### {zh_title}\n\n"
|
||||
changelog_zh += "\n".join(items) + "\n\n"
|
||||
|
||||
# Build English version
|
||||
changelog_en = "## What's Changed (EN)\n\n"
|
||||
for section_key in ["feat", "fix", "perf", "docs", "refactor", "test", "other"]:
|
||||
_, en_title, items = sections[section_key]
|
||||
if items:
|
||||
changelog_en += f"### {en_title}\n\n"
|
||||
changelog_en += "\n".join(items) + "\n\n"
|
||||
|
||||
return changelog_zh + changelog_en
|
||||
|
||||
|
||||
def main() -> None:
|
||||
parser = argparse.ArgumentParser(description="Generate changelog from git commits")
|
||||
parser.add_argument(
|
||||
"--version", help="Version number for the changelog (e.g., v4.13.3)"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use-llm",
|
||||
action="store_true",
|
||||
help="Use LLM to generate changelog (requires OpenAI API key)",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
# Get latest tag
|
||||
try:
|
||||
latest_tag = get_latest_tag()
|
||||
print(f"Latest tag: {latest_tag}")
|
||||
except subprocess.CalledProcessError:
|
||||
print("Error: No tags found in repository")
|
||||
sys.exit(1)
|
||||
|
||||
# Get commits since tag
|
||||
commits = get_commits_since_tag(latest_tag)
|
||||
if not commits:
|
||||
print(f"No commits found since {latest_tag}")
|
||||
sys.exit(0)
|
||||
|
||||
print(f"Found {len(commits)} commits since {latest_tag}")
|
||||
|
||||
# Determine version
|
||||
if args.version:
|
||||
version = args.version
|
||||
else:
|
||||
# Auto-increment patch version
|
||||
match = re.match(r"v(\d+)\.(\d+)\.(\d+)", latest_tag)
|
||||
if match:
|
||||
major, minor, patch = map(int, match.groups())
|
||||
version = f"v{major}.{minor}.{patch + 1}"
|
||||
else:
|
||||
print(f"Warning: Could not parse version from tag {latest_tag}")
|
||||
version = "vX.X.X"
|
||||
|
||||
print(f"Generating changelog for {version}...")
|
||||
|
||||
# Generate changelog
|
||||
if args.use_llm:
|
||||
changelog_content = call_llm_for_changelog(commits, version)
|
||||
else:
|
||||
changelog_content = generate_simple_changelog(commits)
|
||||
|
||||
# Save to file
|
||||
changelog_dir = Path(__file__).parent.parent / "changelogs"
|
||||
changelog_dir.mkdir(exist_ok=True)
|
||||
changelog_file = changelog_dir / f"{version}.md"
|
||||
|
||||
with open(changelog_file, "w", encoding="utf-8") as f:
|
||||
f.write(changelog_content)
|
||||
|
||||
print(f"\n✓ Changelog generated: {changelog_file}")
|
||||
print("\nPreview:")
|
||||
print("=" * 80)
|
||||
print(changelog_content)
|
||||
print("=" * 80)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -2,6 +2,7 @@ from types import SimpleNamespace
|
||||
|
||||
import pytest
|
||||
|
||||
from astrbot.core.provider.sources.groq_source import ProviderGroq
|
||||
from astrbot.core.provider.sources.openai_source import ProviderOpenAIOfficial
|
||||
|
||||
|
||||
@@ -32,6 +33,21 @@ def _make_provider(overrides: dict | None = None) -> ProviderOpenAIOfficial:
|
||||
)
|
||||
|
||||
|
||||
def _make_groq_provider(overrides: dict | None = None) -> ProviderGroq:
|
||||
provider_config = {
|
||||
"id": "test-groq",
|
||||
"type": "groq_chat_completion",
|
||||
"model": "qwen/qwen3-32b",
|
||||
"key": ["test-key"],
|
||||
}
|
||||
if overrides:
|
||||
provider_config.update(overrides)
|
||||
return ProviderGroq(
|
||||
provider_config=provider_config,
|
||||
provider_settings={},
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_handle_api_error_content_moderated_removes_images():
|
||||
provider = _make_provider(
|
||||
@@ -198,6 +214,57 @@ def test_extract_error_text_candidates_truncates_long_response_text():
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_openai_payload_keeps_reasoning_content_in_assistant_history():
|
||||
provider = _make_provider()
|
||||
try:
|
||||
payloads = {
|
||||
"messages": [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": [
|
||||
{"type": "think", "think": "step 1"},
|
||||
{"type": "text", "text": "final answer"},
|
||||
],
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
provider._finally_convert_payload(payloads)
|
||||
|
||||
assistant_message = payloads["messages"][0]
|
||||
assert assistant_message["content"] == [{"type": "text", "text": "final answer"}]
|
||||
assert assistant_message["reasoning_content"] == "step 1"
|
||||
finally:
|
||||
await provider.terminate()
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_groq_payload_drops_reasoning_content_from_assistant_history():
|
||||
provider = _make_groq_provider()
|
||||
try:
|
||||
payloads = {
|
||||
"messages": [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": [
|
||||
{"type": "think", "think": "step 1"},
|
||||
{"type": "text", "text": "final answer"},
|
||||
],
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
provider._finally_convert_payload(payloads)
|
||||
|
||||
assistant_message = payloads["messages"][0]
|
||||
assert assistant_message["content"] == [{"type": "text", "text": "final answer"}]
|
||||
assert "reasoning_content" not in assistant_message
|
||||
assert "reasoning" not in assistant_message
|
||||
finally:
|
||||
await provider.terminate()
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_handle_api_error_content_moderated_without_images_raises():
|
||||
provider = _make_provider(
|
||||
|
||||
Reference in New Issue
Block a user